DDT¶
DDT (Distributed Debugging Tool), a component of the Linaro Forge tool (previously known as Arm Forge or Allinea Forge), is a parallel GUI debugger.
Introduction¶
DDT is a parallel debugger which can be run with up to 2048 processors. It can be used to debug serial, MPI, OpenMP, OpenACC, Coarray Fortran (CAF), UPC (Unified Parallel C) and CUDA codes.
The Forge User Guide available from the official web page or $ALLINEA_TOOLS_DOCDIR/userguide-forge.pdf on Perlmutter after loading a forge module is a good resource for learning advanced DDT features.
Loading the Forge Module¶
To use DDT at NERSC, first load the forge module to set the correct environment settings.
module load forge
But please use the new name since the old name will be removed in the future.
Compiling Code to Run with DDT¶
In order to use DDT, code must be compiled with the -g option. Add the -O0 flag with the Intel compiler. We also recommend that you do not run with optimization turned on, flags such as -fast.
CUDA kernels must be compiled with the -G flag, too, for device side debugging. To use memory debugging with CUDA, -cudart shared must also be passed to nvcc.
Fortran¶
ftn -g -O0 -o testDDT testDDT.f90
C¶
cc -g -O0 -o testDDT testDDT.c
CUDA¶
nvcc -g -G -o testDDT testDDT.cu
Starting a Job with DDT¶
Running an X window GUI application can be painfully slow when it is launched from a remote system over internet. NERSC recommends to use the free ThinLinc software because the performance of the X Window-based DDT GUI can be greatly improved. Another way to cope with the problem is to use a Forge remote client, which will be discussed in the next section.
You can also log in with an X window forwarding enabled, by using using the -X or -Y option to the ssh command. The -Y option often works better for macOS. However, X window forwarding is strongly discouraged because of slow interactive responses. Use the ThinLinc tool or the remote client which is explained below.
After loading the forge module and compiling with the -g (and -G, if needed) option, request an interactive session:
salloc -q interactive -N numNodes -t timeLimit -C gpu .. # Perlmutter GPU
salloc -q interactive -N numNodes -t timeLimit -C cpu .. # Perlmutter CPU
Then launch the debugger with either
ddt ./testDDT
or
forge ./testDDT
where ./testDDT is the name of your program to debug.
The Forge GUI will pop up, showing a start up menu for you to select what to do. For basic debugging, choose the option 'RUN', to run an app under DDT. A user can also choose 'ATTACH' to attach DDT to an already running program, or 'OPEN CORE' to view a core dump file from a previous job.
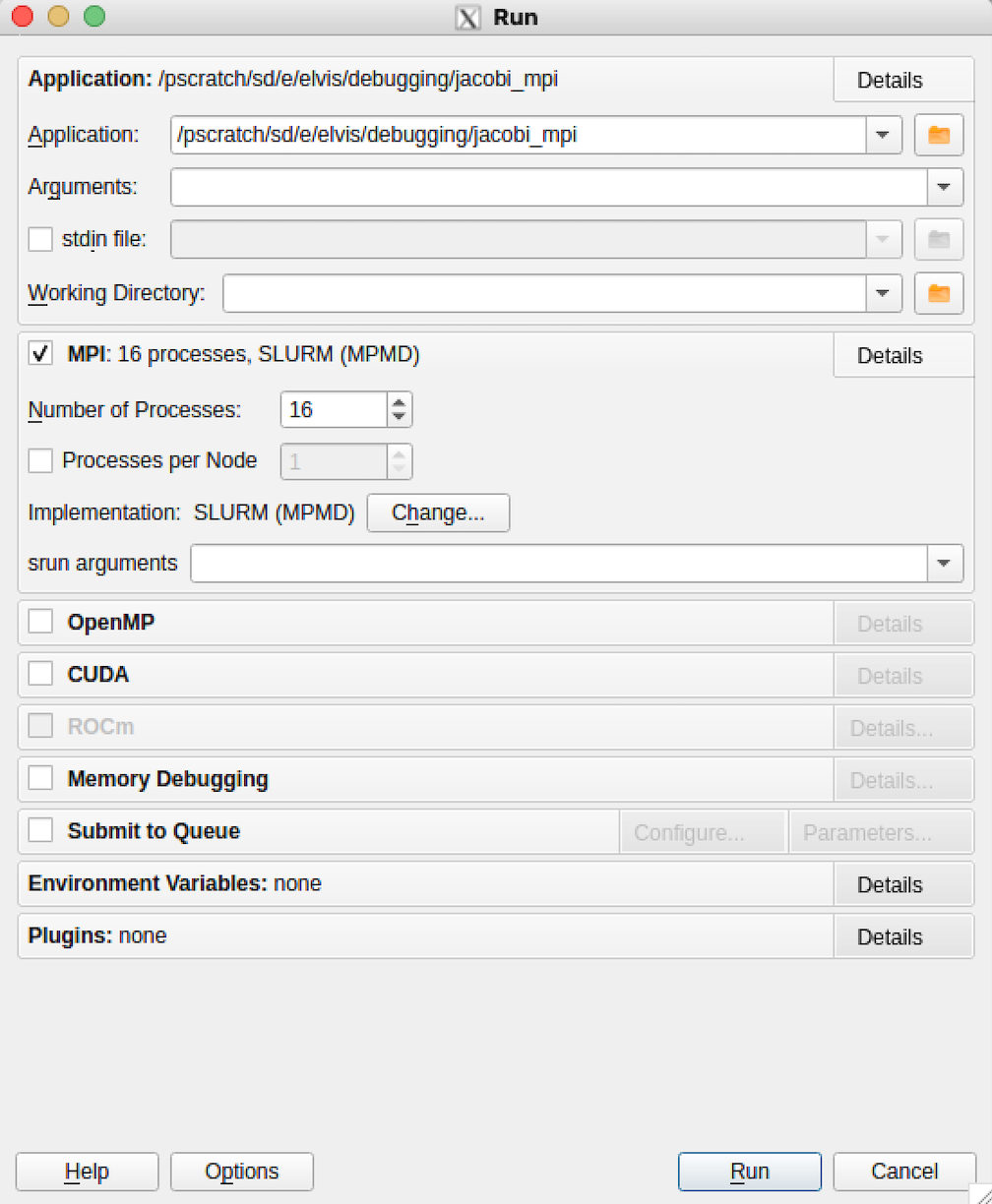
Then the Run window will appear with a pre-filled path to the executable to debug. Select the number of processors on which to run and press run. To pass command line arguments to a program enter them in the 'srun arguments' box.
CUDA Multi-Process Service (MPS) doesn't support debugging. So do not run an application with a debugger such as DDT in an MPS session.
Reverse Connect Using Remote Client¶
If you want to use the ThinLinc tool instead of the remote client, you can skip this section.
Forge remote clients are provided for Windows, macOS and Linux that can run on your local desktop to connect via SSH to NERSC systems to debug, profile, edit and compile files directly on the remote NERSC machine. You can download the clients from Forge download page and install on your laptop/desktop.
Please note that the client version must be the same as the Forge version that you're going to use on the NERSC machines.
First, we need to configure the client for running a debugging session on a NERSC machine. Start the client, and select 'Configure...' in the 'Remote Launch' pull-down menu.
That will open the 'Configure Remote Connections' window.
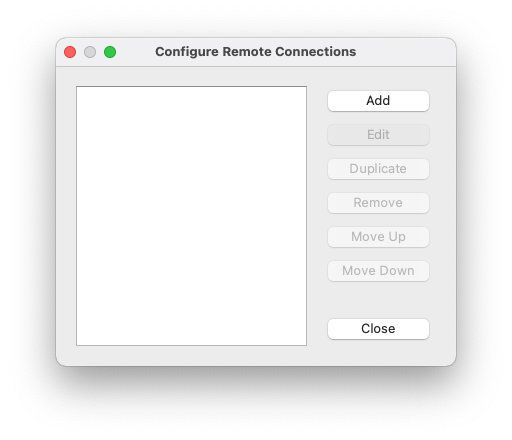
Using the 'Add', 'Edit' and other buttons, create configuration for Perlmutter, as shown in the following example.
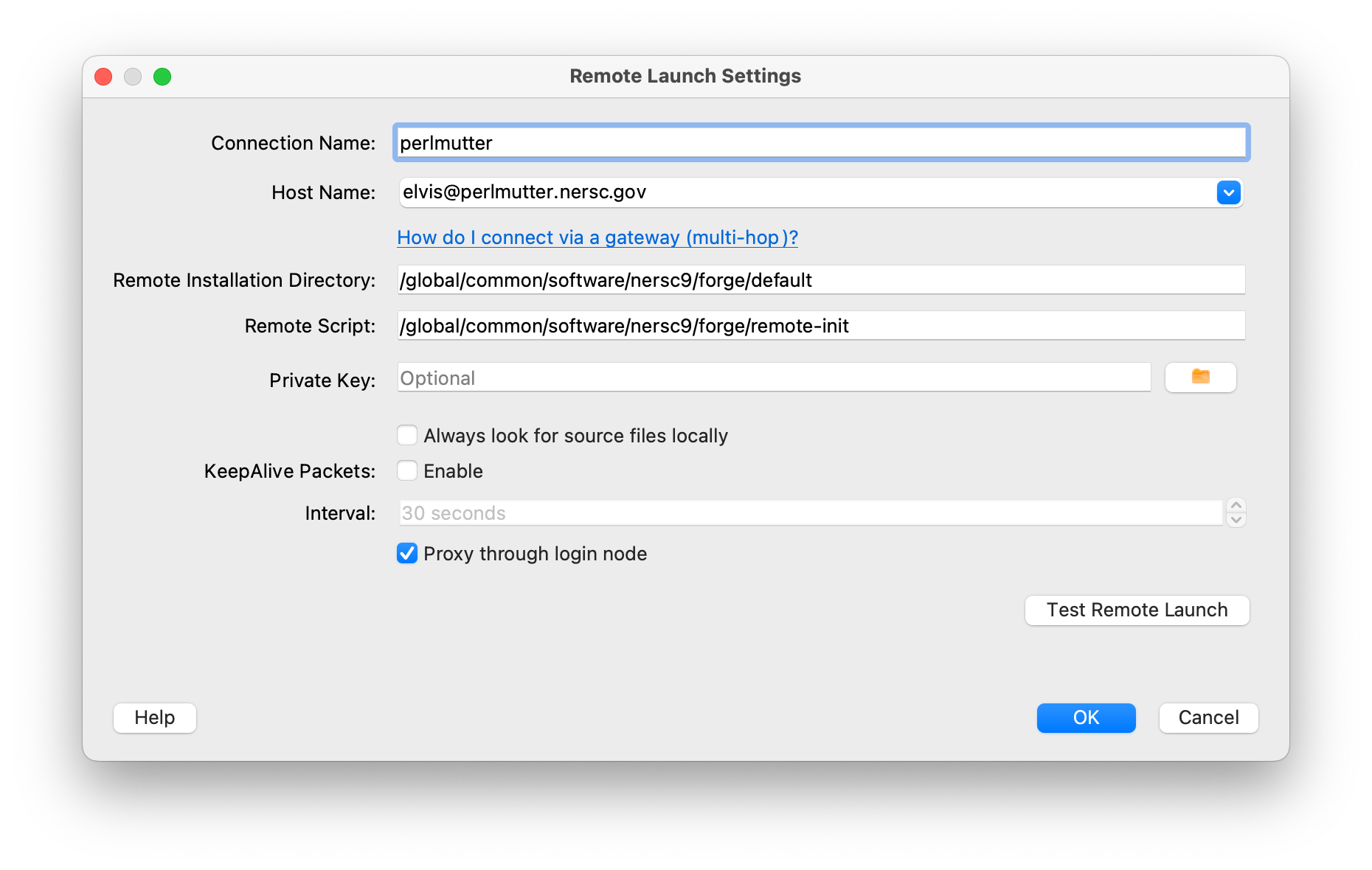
For the 'Remote Installation Directory', use the path for the default forge module. The value for the 'Remote Script' field should be exactly the same as shown above:
- Remote Installation Directory:
/global/common/software/nersc9/forge/default - Remote Script:
/global/common/software/nersc9/forge/remote-init
Click the checkbox for 'Proxy through login node'.
To start a debugging session on a machine, you need to log in to the corresponding machine after choosing the configuration for the machine from the same 'Remote Launch' menu.
You'll be prompted to authenticate with password plus MFA (Multi-Factor Authentication) OTP (One-time password):
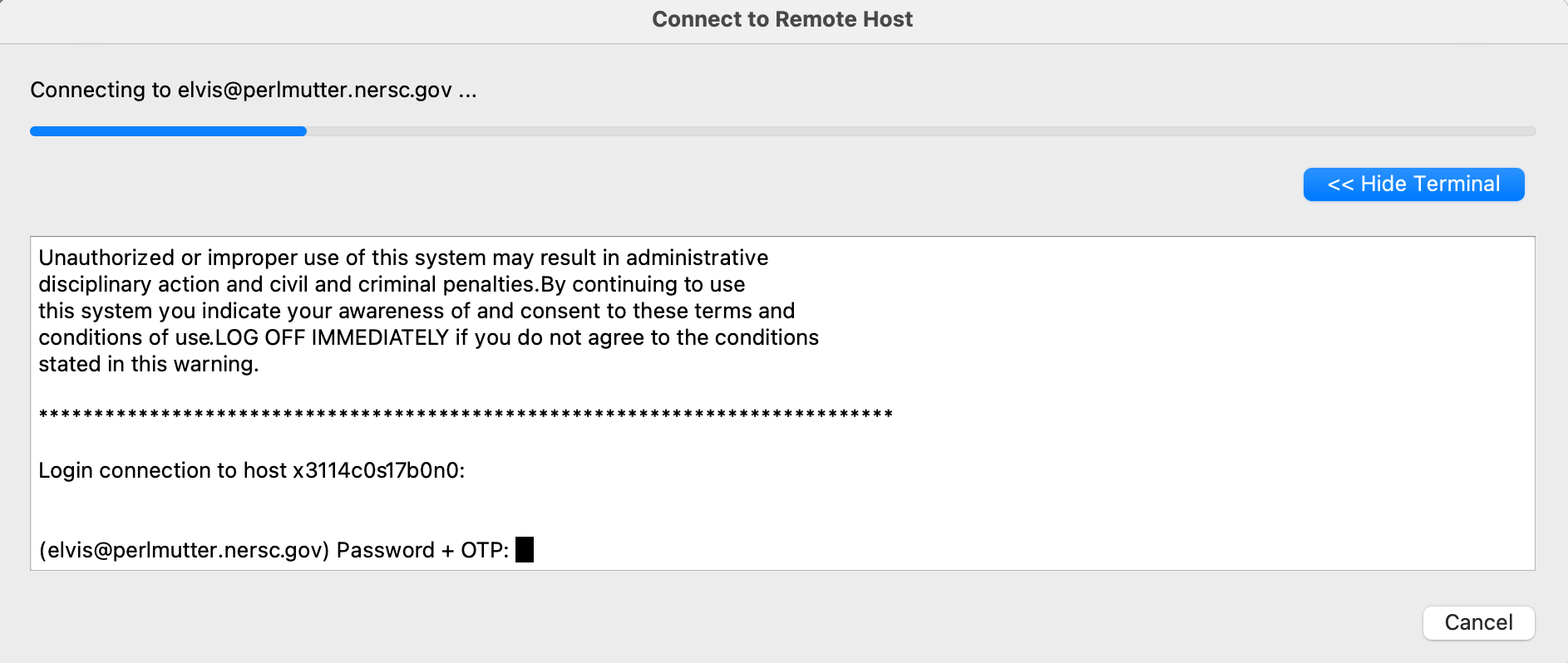
If you have set up ssh to use the ssh keys generated by sshproxy as shown in MFA page's 'Ssh Configuration File Options' section and the keys have not expired, the remote client will connect to the desired machine without you entering password and OTP.
It is recommended to use the Reverse Connection method with the remote client. To do this, put aside the remote client window that you have been working with, and log in to the corresponding machine from another window on your local machine, as you would normally do.
ssh perlmutter.nersc.gov # Perlmutter
Then, start an interactive batch session there. For example,
salloc -N 2 -G 8 -t 30:00 -q debug -C gpu -A ... # Perlmutter GPU
and run DDT with with the option --connect as follows:
module load forge
ddt --connect srun -n 32 -c 16 --cpu-bind=cores ./jacobi_mpi
The remote client will ask you whether to accept a Reverse Connect request. Click 'Accept'.
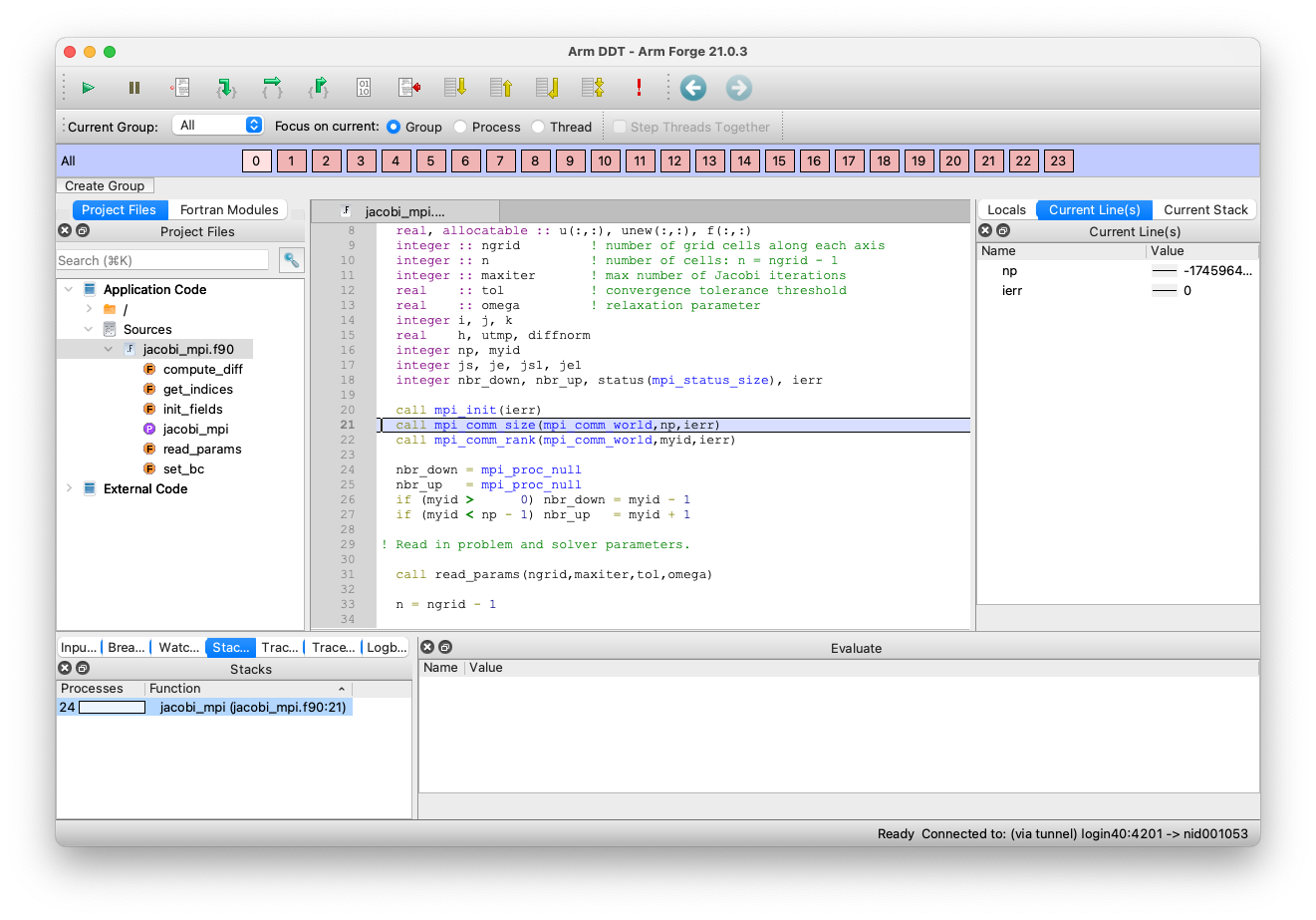
The usual Run window, as shown near the top of this webpage, will appear where you can change or set run configurations and debugging options. Click 'Run'.
Now, you can start debugging in the remote client:
Troubleshooting¶
If you are having trouble launching DDT try these steps.
Make sure you have the most recent version of the system.config configuration file. The first time you run DDT, you pick up a master template which then gets stored locally in your home directory in ~/.allinea/${NERSC_HOST}/system.config where ${NERSC_HOST} is the machine name. If you are having problems launching DDT you could be using an older version of the system.config file and you may want to remove the entire directory:
rm -rf ~/.allinea/${NERSC_HOST}
Remove any stale processes that may have been left by DDT.
rm -rf $TMPDIR/allinea-$USER
In case of a font problem where every character is displayed as a square, please delete the .fontconfig directory in your home directory and restart ddt.
rm -rf ~/.fontconfig
Make sure you are requesting an interactive batch session. NERSC has configured DDT to run from the interactive batch jobs.
salloc -A <allocation_account> -N numNodes -C gpu -q interactive -t 30
Finally make sure you have compiled your code with -g. A large number of users who are having trouble running with parallel debuggers forget to compile their codes with debugging flags turned on.
Basic Debugging Functionality¶
The DDT GUI interface should be intuitive to anyone who has used a parallel debugger like Totalview before. Users can set breakpoints, step through code, set watches, examine and change variables, dive into arrays, dereference pointers, view variables across processors, step through processors etc. Please see the official web page if you have trouble with any of these basic features.
Memory Debugging¶
DDT has a memory debugging tool that can show heap memory usage across processors.
Dynamic linking is the default mode of linking on Perlmutter, and we explain how to build in case of dynamic linking here. For static linking, please check the user manual.
The example is provided for a Fortran code case. Adjustments should be made for C and C++ codes accordingly.
Build as usual, but link with the -zmuldefs flag as follows:
ftn -g -c prog.f
ftn -o prog prog.o -zmuldefs
Next, when DDT starts, you must click the 'Memory Debugging' checkbox in the DDT run menu that first comes up.
To set detailed memory debugging options, click the 'Details...' button on the far right side, which will open the 'Memory Debugging Options' window. There you can set the heap debugging level, the number of guard pages before or after arrays (but not both) for detection of heap overflow or underflow in the program, etc. The default page size is 4 KB.
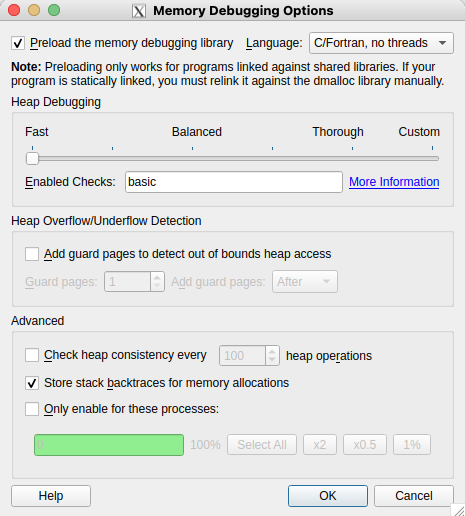
Click the 'Preload the memory debugging library' checkbox at the top for a dynamically-linked executable. When running DDT with a statically built code, you need to deselect the 'Preload the memory debugging library' item. Otherwise, DDT can hang indefinitely during startup on Cray machines.
Also select the proper language and threading item from the pull-down menu right next to it.
Several features are enabled with memory debugging. Select 'Current Memory Usage' or 'Memory Statistics' under the 'Tools' menu. With the following buggy code that generates memory leaks, you can easily see heap memory information (such as how much is being used, how much has been allocated, how much is freed, etc.), from which you can deduce where memory leaks occur.
program memory_leaks
!... Buggy code prepared by NERSC User Service Group for a debugging tutorial
!... February, 2012
implicit none
include 'mpif.h'
integer, parameter :: n = 1000000
real val
integer i, ierr
call mpi_init(ierr)
val = 0.
do i=1,10
call sub_ok(val,n)
end do
do i=1,10
call sub_bad(val,n)
end do
do i=1,10
call sub_badx2(val,n)
end do
print *, val
call mpi_finalize(ierr)
end
subroutine sub_ok(val,n) ! no memory leak
integer n
real val
real, allocatable :: a(:)
allocate (a(n))
call random_number(a)
val = val + sum(a)
deallocate(a)
end
subroutine sub_bad(val,n) ! memory leak of 4*n bytes per call
integer n
real val
real, pointer :: a(:)
allocate (a(n))
call random_number(a)
val = val + sum(a)
! deallocate(a) ! not ok not to deallocate
end
subroutine sub_badx2(val,n) ! memory leak of 8*n bytes per call
integer n
real val
real, pointer :: a(:)
allocate (a(n))
call random_number(a)
val = val + sum(a)
allocate (a(n)) ! not ok to allocate again
call random_number(a)
val = val + sum(a)
! deallocate(a) ! not ok not to deallocate
end
Below is a window shown when the 'Current Memory Usage' menu is selected:
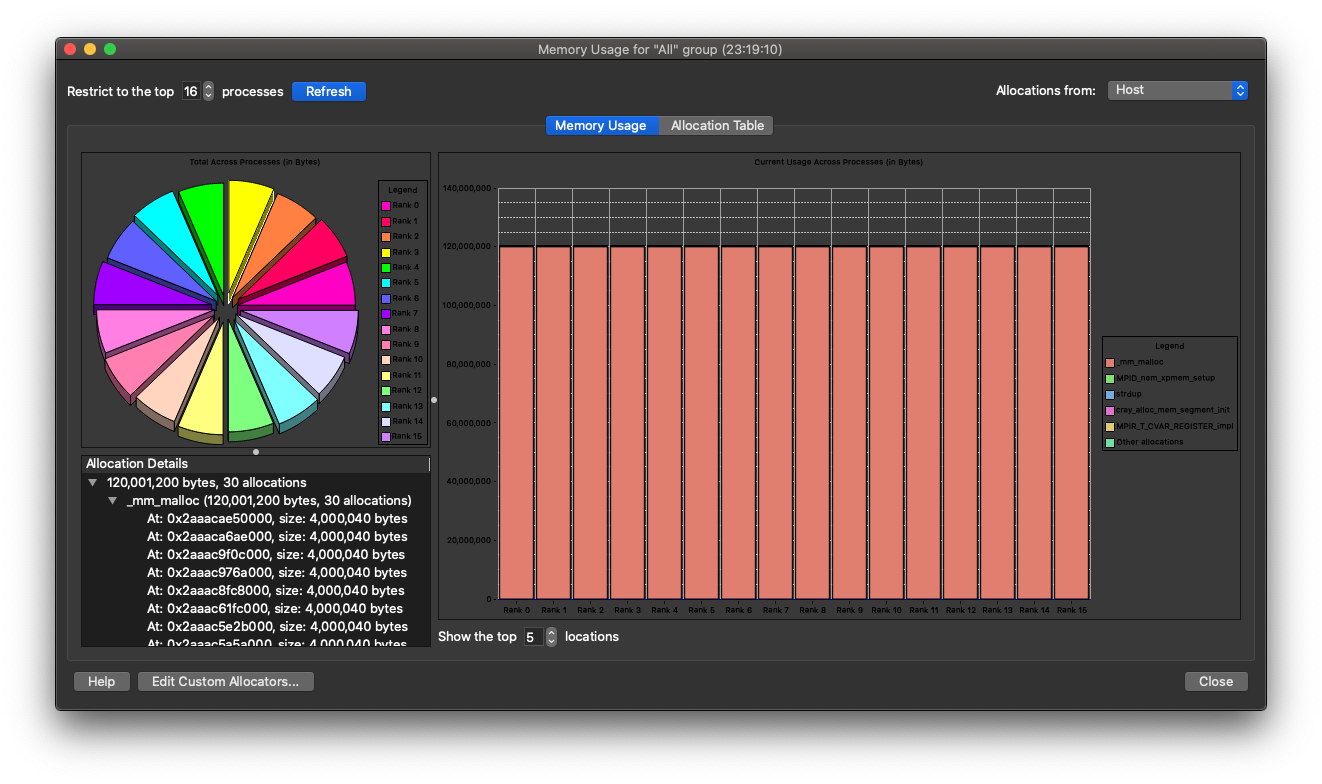
It displays current heap memory usage of the program and the routines where it is allocated. Clicking on a histogram bar on the right, you will see the 'Allocation Details' box on the left filled up with information about where the memory allocation was made. By clicking on one of the pointers in the 'Allocation Details' list you can get information mapped to source code:
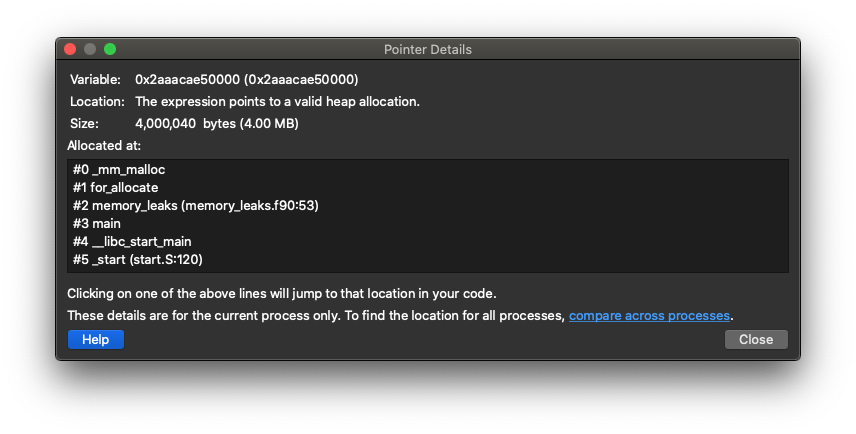
It shows how much It is known that memory debugging can fail with the error message 'A tree node closed prematurely. One or more processes may be unusable.', especially with MPI_Bcast. A workaround is to disable 'store stack backtraces for memory allocations' option in the 'Enable Memory Debugging' setting. This problem will be fixed in the next release.
CUDA Debugging¶
To enable CUDA debugging, you need to check the CUDA box in the Run window before you click the 'Run' button.
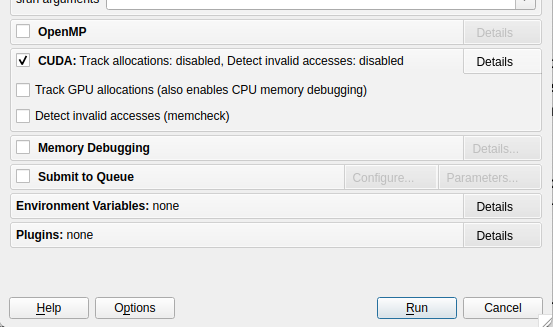
It is possible to run memory debugging on a CUDA code by checking the Track GPU allocations (also enable CPU memory debugging) option box. Then, CUDA memory allocations made by the host are tracked. That is, allocations made using functions such as cudaMalloc. As indicated, this option automatically enables memory debugging for the CPU side, too.
The Detect invalid accesses (memcheck) option turns on the CUDA memcheck (that is, Compute Sanitizer) error detection tool. This tool can detect problems such as out-of-bounds and misaligned global memory accesses, and syscall errors, such as calling free() in a kernel on an already free'd pointer. The other CUDA hardware exceptions are detected regardless of whether this option is selected or not. Please check the Compute Sanitizer manual for details.
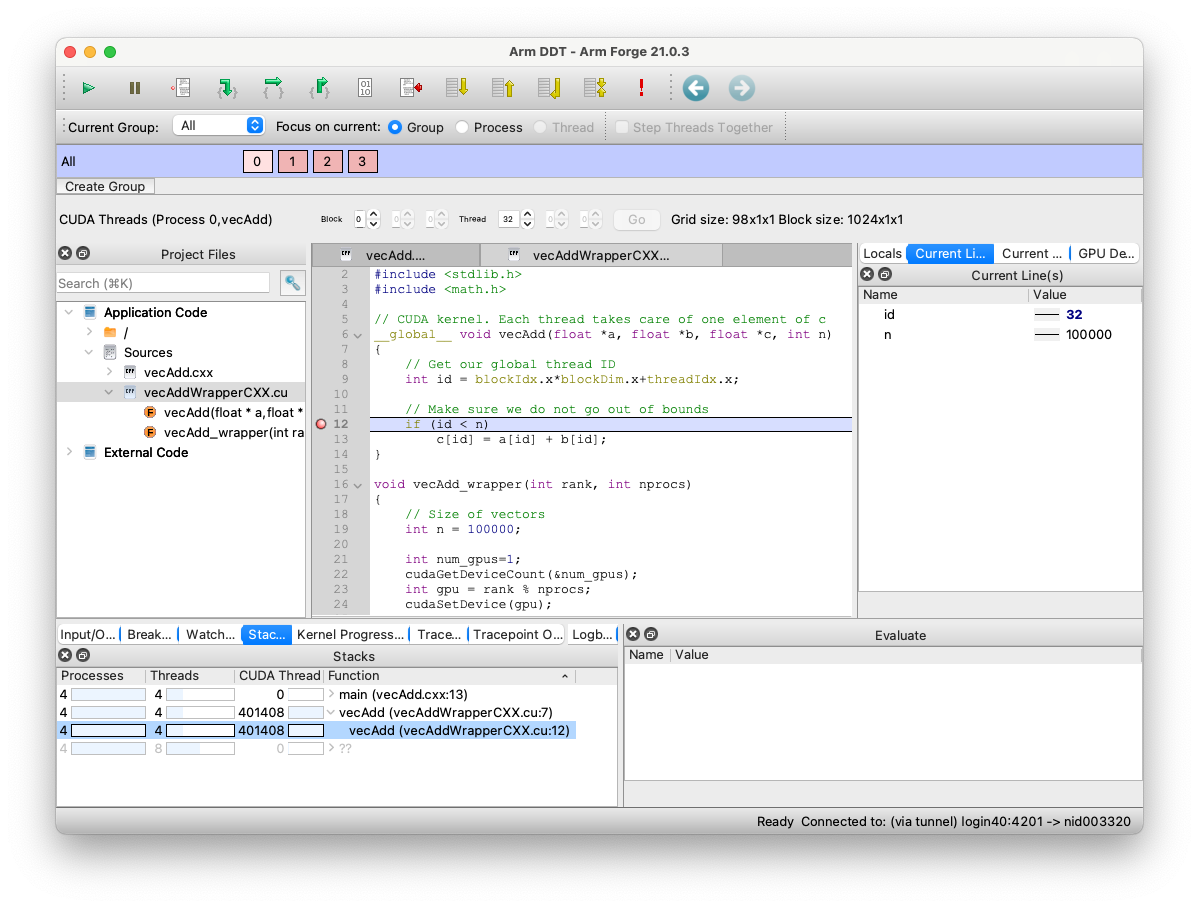
The Thread Selector enables you to select your current GPU thread. The current thread is used for the variable evaluation windows, along with the various GPU stepping operations.

Breakpoints affect all GPU threads, and cause the program to stop when a thread reaches the breakpoint. Where kernels have similar workload across blocks and grids, threads tend to reach the breakpoint together and the kernel pauses once per set of blocks that are scheduled, that is, the set of threads that fit on the GPU at any one time. Where kernels have divergent distributions of work across threads, timing may be such that threads within a running kernel hit a breakpoint and pause the kernel. After continuing, more threads within the currently scheduled set of blocks will hit the breakpoint and pause the program again. The smallest execution unit on a GPU is a warp.
Clicking the Play/Continue button runs all GPU threads. Clicking the Pause button pauses a running kernel.
To apply breakpoints to individual blocks, warps, or threads, conditional breakpoints can be used.
Where a kernel pauses at a breakpoint, the currently selected GPU thread will be changed if the previously selected thread is no longer active.
The Parallel Stack View displays the location and number of GPU threads.
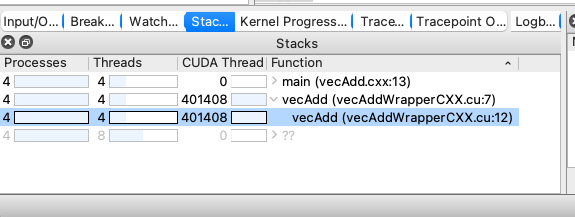
You can use the Kernel Progress View, which is displayed at the bottom of the user interface by default when a kernel is in progress. When you click in the color highlighted sections of the progress bar, a GPU thread will be selected that matches the click location as closely as possible. Selected GPU threads are colored blue. For deselected GPU threads, the ones that are scheduled are colored green (darker green means more active kernels), and the unscheduled ones are white.
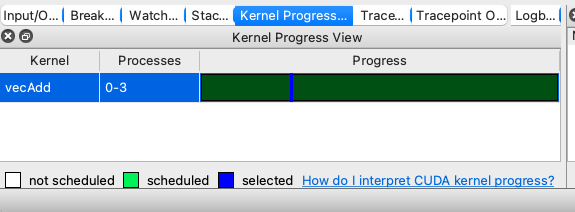
The GPU Devices tab examines the GPUs that are present and in use across a program, and groups the information together scalably for multi-process systems.
Offline Debugging¶
Offline debugging is to run DDT in a command-line mode, without using GUI. This mode may be useful if all you want is to get tracepoint (a specified location in the code where requested values are printed) output or stack backtraces without directly interacting with DDT. This can be good for a "parameter study" where you want to check for an error condition for a range of a parameter value, which would become a tedious task if GUI is used.
To run DDT in this mode, you submit a batch job using a batch script ("runit") that looks like:
#!/bin/bash
#SBATCH ...
module load forge
ddt --offline -o filename.html srun -n 4 myprogram arg1 ... # to get HTML output file
ddt --offline -o filename srun -n 4 myprogram arg1 ... # to get plain text output file
which is submitted via sbatch:
sbatch runit
Please note that we are using ddt --offline ... in place of srun or mpirun for launching an application. Output of the debugging session is saved in the specified file (filename.html or filename in the above example).
Add srun-related flags to the ddt command.
DDT doesn't pass srun-related SBATCH directive parameters in a batch submit script ('#SBATCH -c 32', '#SBATCH --gpus-per-task=1', etc.) to the srun command. These options should be added to the srun part in the ddt command directly (for example, ddt --offline ... srun -n 8 -c 32 --gpus-per-task=1 .... Otherwise, the ddt command may fail with the following error message:
srun: error: task 0 launch failed: Error configuring interconnect
srun: error: task 2 launch failed: Error configuring interconnect
...
Some options can be used for the ddt command:
Start offline debugging flags with double dash
The user guide of the 23.0 version uses double dashes when specifying offline debugging options. That is, it uses --mem-debug, instead of previous -mem-debug. Both seem to work, but we recommend to use the double-dash form moving forward.
-
--session=<sessionfile>: run using settings saved using the 'Save Session' option during a previous GUI run session -
--processes=<numTasks>: run withnumTasks(MPI) tasks -
--mem-debug[=fast|balanced|thorough|off]: enable memory debugging -
--snapshot-interval=<MINUTES>: write a snapshot of the program's stack and variables every MINUTES minutes. -
--trace-at=<LOCATION[,N:M,P],VAR1,VAR2,...> [if <CONDITION>]: set a tracepoint at locationLOCATION(given by either 'filename:linenumber' orfunctionnameas inmain.c:22ormyfunction), beginning recording after the N-th visit of each process to the location, and recording every M-th subsequent pass until it has been triggered P times; record the value of variableVAR1,VAR2, ...; the if clause allows to specify a booleanCONDITIONthat must be satisfied to trigger the tracepoint -
--break-at=<LOCATION[,N:M:P]> [if <CONDITION>]: set a breakpoint at a location using the format explained above; the stack back traces of pausing processes will be recorded at the breakpoint before they are then made to continue -
--evaluate=<EXPRESSION[;EXPRESSION2][;...]>: set one or more expressions to be evaluated on every program pause -
--offline-frames=(all|none|<n>): specify how many frames to collect variables for
An example using the following simple code is shown below:
program offline
!... Prepared for a debugger tutorial by NERSC
include 'mpif.h'
integer, parameter :: n = 24
real, allocatable :: a(:)
integer i, me
call mpi_init(ierr)
call mpi_comm_rank(mpi_comm_world,me,ierr)
allocate (a(n))
call random_number(a)
do i=1,n
if (mod(i,2) == 1) call sub(i,n,a) ! 'sub' called when i=1,3,5,...
end do
print *, me, sum(a)
deallocate(a)
call mpi_finalize(ierr)
end
subroutine sub(i,n,a)
integer n, i, j
real a(n)
do j=1,n
a(j) = cos(a(j))
end do
end
The following is to set a tracepoint at the beginning of the routine sub where values of i and a(1) are to be printed; and to set a breakpoint at line 23, using the activation scheme of '5:3:2':
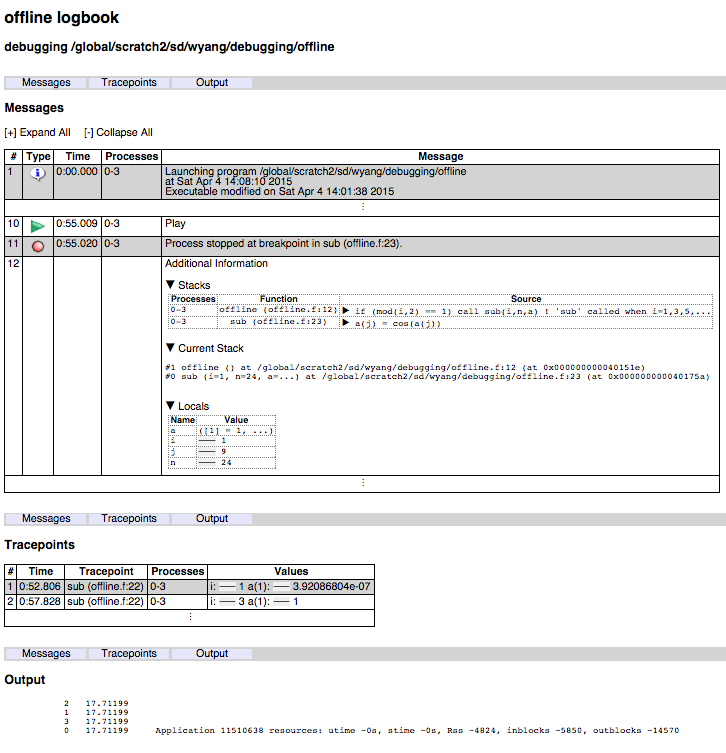
ddt --offline -o offline.html --trace-at=sub,i,a\(1\) --break-at=offline.f:23,5:3:2 srun -n 4 ./offline
The output file is broken into three sections: 'Messages' (showing process activities such as startup and termination etc., as well as call backtrace at breakpoints), 'Tracepoints' (showing output from activated tracepoints), and 'Output' (program output).
Useful DDT Features¶
Process Groups¶
With DDT, the user can easily change the debugger to focus on a single process or group of processes. If Focus on current Processor is chosen, then stepping through the code, setting a breakpoint etc will occur only for a given processor. If Focus on current Group is chosen then the entire group of processors will advance when stepping forward in a program and a breakpoint will be set for all processors in a group.

Similarly, when Focus on current Thread is chosen, then all actions are for an OpenMP thread. DDT doesn't allow to create a thread group. However, one can click the Step Threads Together box to make all threads to move together inside a parallel region. In the image shown above, this box is grayed out simply because the code is not an OpenMP code.
A user can create new sub-groups of processors in several ways. One way is to click on the 'Create Group' button at the bottom of the 'Process Group Window'. Another way is to right-click in the 'Process Group Window' to create a group and then drag the desired processors to the group. Groups can also be created more efficiently using sub-groups from the 'Parallel Stack View' described below. The below image shows 3 different groups of processors, the default All group, a group with only a single master processor 'Master' and a group with the remaining 'Workers' processors.

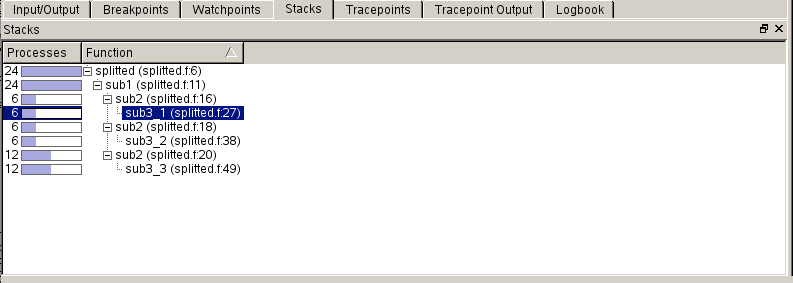
Parallel Stack View¶
A feature which should help users debug at high concurrencies is DDT's 'Parallel Stack View' window found in the lower left area, which allows the user to see the position of all processors in a code at the same time from the main window. A program is displayed as a branching tree with the number and location of each processor at each point. Instead of clicking through windows to determine where each processor has stopped, the 'Parallel Stack View' presents a quick overview which easily allows users to identify stray processes. Users can also create sub-groups of processors from a branch of the tree by right clicking on the branch. A new group will appear in the 'Process Group Window' at the top of the GUI.