Perlmutter Architecture¶

Perlmutter is a HPE (Hewlett Packard Enterprise) Cray EX supercomputer, named in honor of Saul Perlmutter, an astrophysicist at Berkeley Lab who shared the 2011 Nobel Prize in Physics for his contributions to research showing that the expansion of the universe is accelerating. Dr. Perlmutter has been a NERSC user for many years, and part of his Nobel Prize-winning work was carried out on NERSC machines and the system name reflects and highlights NERSC's commitment to advancing scientific research.
Perlmutter, based on the HPE Cray Shasta platform, is a heterogeneous system comprised of 3,072 CPU-only and 1,792 GPU-accelerated nodes.
System Specifications¶
| Partition | # of nodes | CPU | GPU | NIC |
|---|---|---|---|---|
| GPU | 1536 | 1x AMD EPYC 7763 | 4x NVIDIA A100 (40GB) | 4x HPE Slingshot 11 |
| 256 | 1x AMD EPYC 7763 | 4x NVIDIA A100 (80GB) | 4x HPE Slingshot 11 | |
| CPU | 3072 | 2x AMD EPYC 7763 | - | 1x HPE Slingshot 11 |
| Login | 40 | 2x AMD EPYC 7713 | 1x NVIDIA A100 (40GB) | - |
System Performance¶
| Partition | Type | Aggregate Peak FP64 (PFLOPS) | Aggregate Memory (TB) |
|---|---|---|---|
| GPU | CPU | 4.5 | 448 |
| GPU | GPU | 69.5 tensor: 140 | 328 |
| CPU | CPU | 15.4 | 1536 |
Interconnect¶
The network has a 3-hop dragonfly topology.
- A GPU compute cabinet is segmented into 8 chassis, each containing 8 compute blades and 4 switch blades.
- A GPU compute blade contains 2 GPU-accelerated nodes.
- GPU-accelerated compute cabinets have Slingshot 11 interconnect fabric with HPE Cray's proprietary Cassini NICs.
- Each GPU-accelerated compute node is connected to 4 NICs.
- GPU cabinets contain 32 switch blade across two 16-switch Dragonfly groups.
- A CPU-only compute cabinet has 8 chassis, each containing 8 compute blades and 2 switch blades.
- A CPU-only compute blade contains 4 CPU nodes.
- Each CPU-only compute node is connected to 1 NIC.
- CPU-only cabinets contain one 16-switch Dragonfly group per cabinet.
- CPU compute cabinets have Slingshot 11 interconnect fabric with Cassini NICs.
- There is no backplane in the chassis to provide the network connections between the compute blades. Network connections are achieved by having the switch blades at the rear of the cabinet, providing the interconnection between the compute blades in the in the front side.
- A full all-to-all electrical network is provided within each group. All switches in a switch group are directly connected to all other switches in the group.
- Copper Level 0 (L0) cables connect nodes to network switches. L0 cables carry two links and are split to provide two single link node connections. L0 links are called "host links" or "edge links".
- Copper Level 1 (L1) cables are used to interconnect the switches within a group. The 16-switch groups are internally interconnected with two cables (four links) per switch pair. L1 links are called "group links" or "local links".
- Optical Level 2 (L2) cables interconnect groups within a subsystem (e.g., the compute subsystem consisting of compute nodes). L2 links are called "global links". Each optical cable carries two links per direction.
- L2 cables also interconnect subsystems - there are 3 subsystem on a HPE Cray EX system, each with its own dragonfly interconnect topology: compute, IO, and service subsystems.
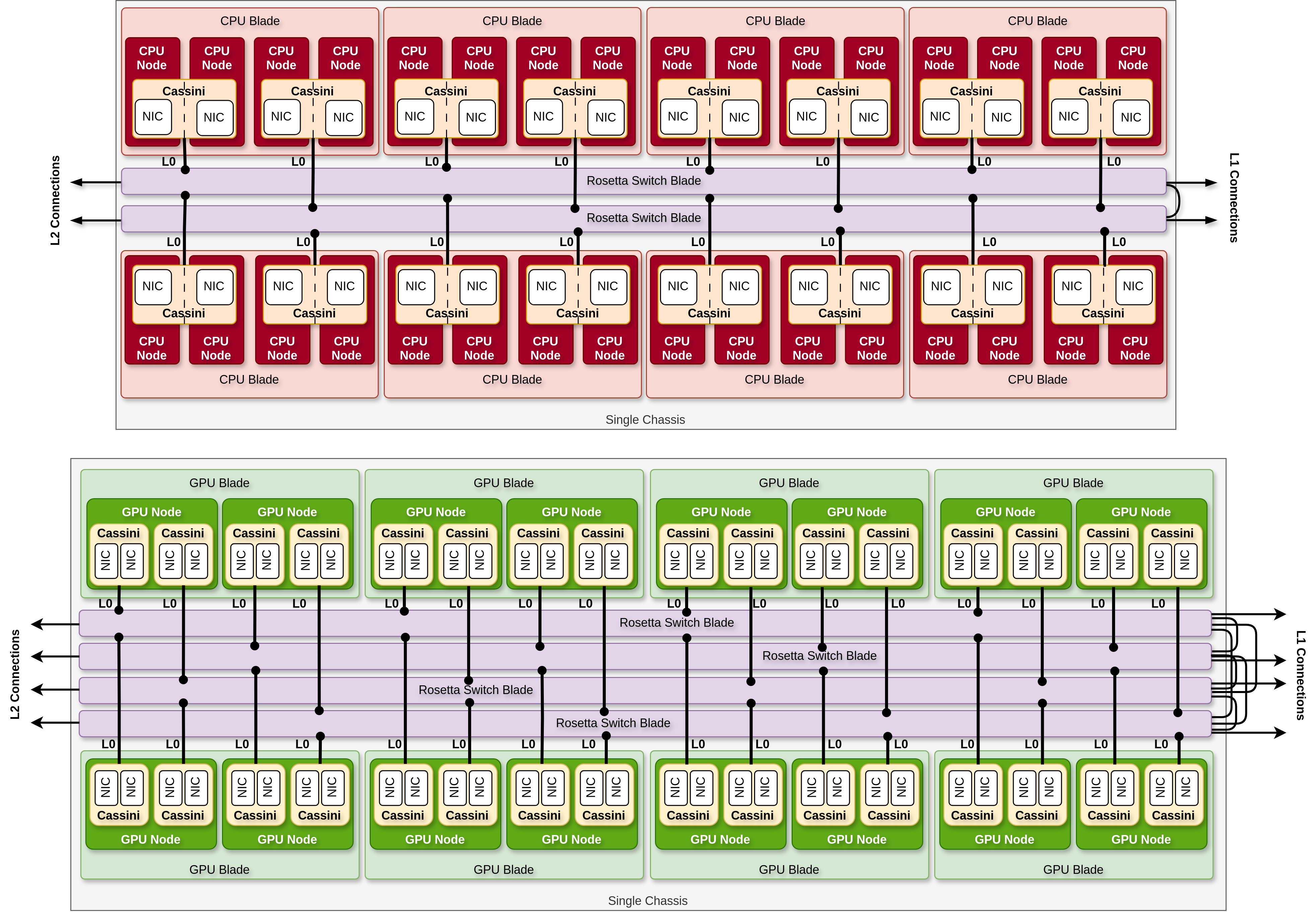 |
|---|
| Figure: (Top) Diagram of a single CPU compute chassis showing network switches and connection types. (Bottom) Diagram of a single GPU compute chassis. |
NIC¶
- PCIe 4.0 connection to nodes
- 200G (25 GB/s) bandwidth
- 1x NIC per node for CPU partition
- 4x NICs per node for GPU partition
Node Specifications¶
GPU nodes¶
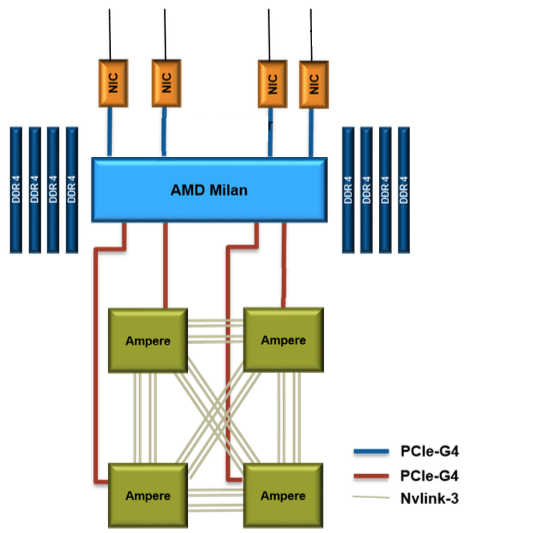

- Single AMD EPYC 7763 (Milan) CPU
- 64 cores per CPU
- Four NVIDIA A100 (Ampere) GPUs
- PCIe 4.0 GPU-CPU connection
- PCIe 4.0 NIC-CPU connection
- 4 HPE Slingshot 11 NICs
- 256 GB of DDR4 DRAM
- 204.8 GB/s CPU memory bandwidth
- 1555 GB/s GPU memory bandwidth per 40GB HBM2 GPU and 2039 GB/s GPU memory bandwidth per 80GB HBM2e GPU
- 4 third generation NVLink connections between each pair of GPUs
- 25 GB/s/direction for each link
| Data type | GPU TFLOPS |
|---|---|
| FP32 | 19.5 |
| FP64 | 9.7 |
| TF32 (tensor) | 155.9 |
| FP16 (tensor) | 311.9 |
| FP64 (tensor) | 19.5 |
Further details:
CPU Nodes¶
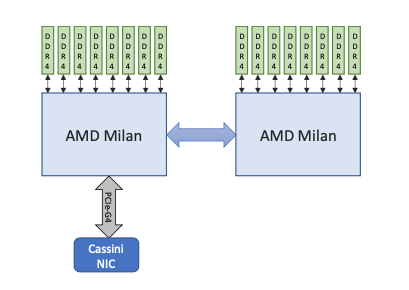
- 2x AMD EPYC 7763 (Milan) CPUs
- 64 cores per CPU
- AVX2 instruction set
- 512 GB of DDR4 memory total
- 204.8 GB/s memory bandwidth per CPU
- 1x HPE Slingshot 11 NIC
- PCIe 4.0 NIC-CPU connection
- 39.2 GFlops per core
- 2.51 TFlops per socket
- 4 NUMA domains per socket (NPS=4)
Further details:
Login nodes¶
- 2x AMD EPYC 7713 (Milan) CPUs
- 512 GB of memory in total
- 1x NVIDIA A100 GPU with 40 GiB of memory
- Two NICs connected via PCIe 4.0
- 960 GB of local SSD scratch
- 1 NUMA node per socket (NPS=1)
Storage¶
The Perlmutter Scratch File System is an all-flash file system. It has 44 PB of disk space, an aggregate bandwidth of 7.8 TB/sec (reads) and 6.6 TB/s (writes), and 4 million IOPS (4 KiB random). It has 16 MDS (metadata servers) and 370 I/O servers called OSSs.