Jupyter at NERSC: Reference¶
Available Configurations¶
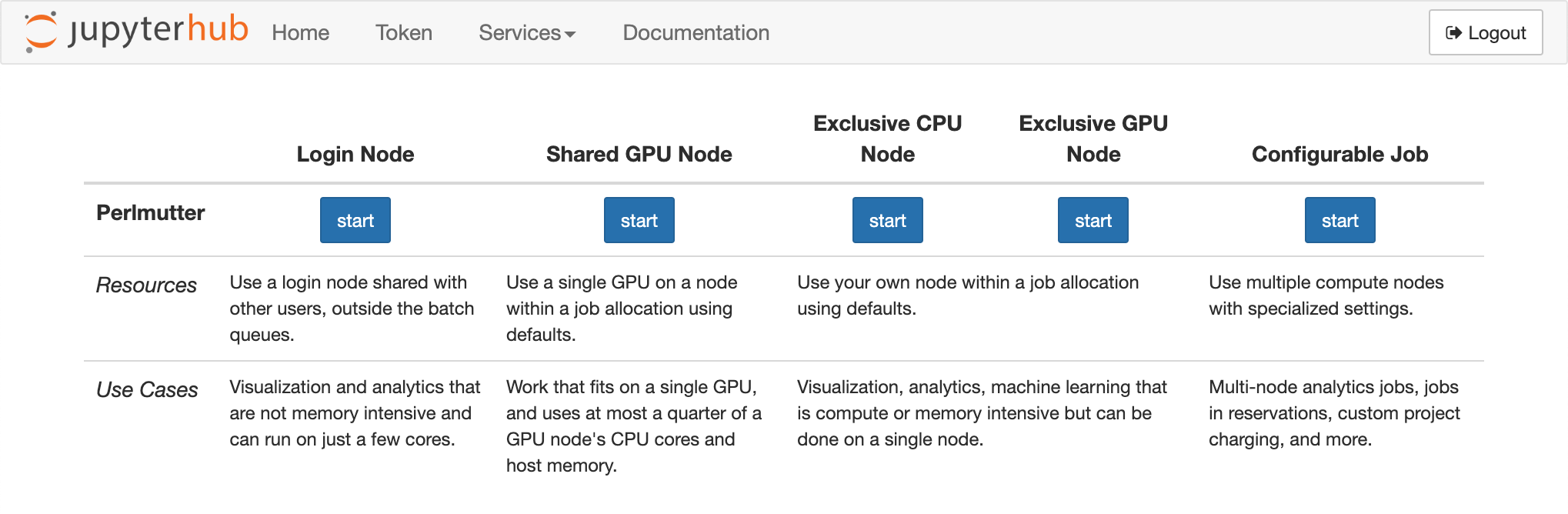
| Name | Resources | Project Charged | Persistence |
|---|---|---|---|
| Login Node | Login node | N/A | Culled after idling up to 16 hours |
| Shared GPU Node | 1/4 GPU compute node: 1 GPU, 1/4 CPU cores & host memory | Default project | Duration of batch job |
| Exclusive CPU Node | 1 CPU compute node | Default project | Duration of batch job |
| Exclusive GPU Node | 1 GPU compute node: 4 GPUs, all CPU cores & host memory | Default project | Duration of batch job |
| Configurable | 1-4 CPU or GPU compute nodes | User's discretion | Duration of batch job |
Login Nodes¶
Using JupyterHub to spawn JupyterLab on a login node is the most common way that people use Jupyter at NERSC. These nodes are the same ones that you use when you connect to a NERSC supercomputer via SSH or ThinLinc. When you use JupyterLab on a login node, you have access to all the same resources you would have if you logged in those other ways. You can access the same file systems (NGF and $SCRATCH platform storage), and you can submit jobs to the batch queue.
Use of JupyterLab on login nodes is subject to the same kinds of resource limits as are enforced for users logging in via SSH because the login nodes are shared by many users at the same time. JupyterLab servers that are idle for a long time are shut down automatically.
Running JupyterLab on a login node is a good option for debugging, lightweight interactive data exploration and analysis, or as a platform from which to launch and manage more complex workflows. On the other hand, it should not be used for large-scale parallel compute or long-running computations.
Compute Nodes, Shared or Exclusive¶
If you use JupyterHub to spawn JupyterLab on a compute node, it will run in a batch job allocated by Slurm. When you use JupyterLab on a compute node, you have access to all the same resources you would have if you ran an interactive job. You can access the same file systems (NGF and $SCRATCH platform storage) and interact with Slurm.
In order for the JupyterHub to both spawn a compute node server and poll the status of the scheduler job associated with that compute node server, it needs to be able to parse the output from commands run to query Slurm. Because these query commands are run from the JupyterHub accessing the supercomputer via SSH, we recommend that any customizations in your dotfiles which generate output upon login (e.g., an echo or module swap command) go in your ~/.bash_profile file (or other shell equivalent) and not the ~/.bashrc file. The former is not directly sourced in the JupyterHub compute node server workflow, while the latter is, so any output coming from ~/.bashrc or an equivalent file can interfere with the JupyterHub being able to start a compute node job.
You may need to wait a few minutes for resources to become available for running your JupyterLab job. If resources are not allocated within 10 minutes of your request, it is canceled by JupyterHub and you can try again. JupyterLab servers at NERSC that run in the batch queue have a large priority boost and can preempt jobs in preemptable QOSes if necessary to get resources. If the system is busy or the preemptable workload is shallow, it becomes harder to provide resources for JupyterLab on compute nodes. We track the rate at which requests for resources for JupyterLab jobs fail and adjust queue policy or preemption incentives to mitigate spawn failures.
Jobs submitted to GPU compute nodes may be shared or allocated exclusively. CPU nodes are exclusive-use only. For instance, a shared GPU node JupyterLab server will be allocated one GPU and a corresponding fraction of CPUs and memory on the node (e.g. 1 GPU out of 4, 1/4 of all the CPU cores, 1/4 of all the host memory). Other user jobs may be running on the same node in this case. A user allocated a node exclusively has access to all the hardware on the node. Shared node jobs are more economical for users who don't need all the resources on a compute node but need more steady access to hardware resources than they can get on login nodes. The trade-offs to using the compute nodes are:
- Your JupyterLab server shuts down at the end of the batch job; on a login node it is more persistent.
- Batch-based JupyterLab usage is charged to your default project; on a login node JupyterLab runs without any charging.
Visit the QOSes and charges page to see the time limits and charge factors for the jupyter QOS, and check Iris to identify or update your default project.
Configurable Jobs¶
The shared and exclusive compute node options rely on default logic to make start-up of JupyterLab on the compute nodes with sensible settings a single-click proposition. But you might want to charge to a different project than your default, request different job parameters, run JupyterLab in a reservation, or use more than one node. The "configurable" option presents you a menu that lets you adjust the batch job parameters to make these kinds of adjustments:
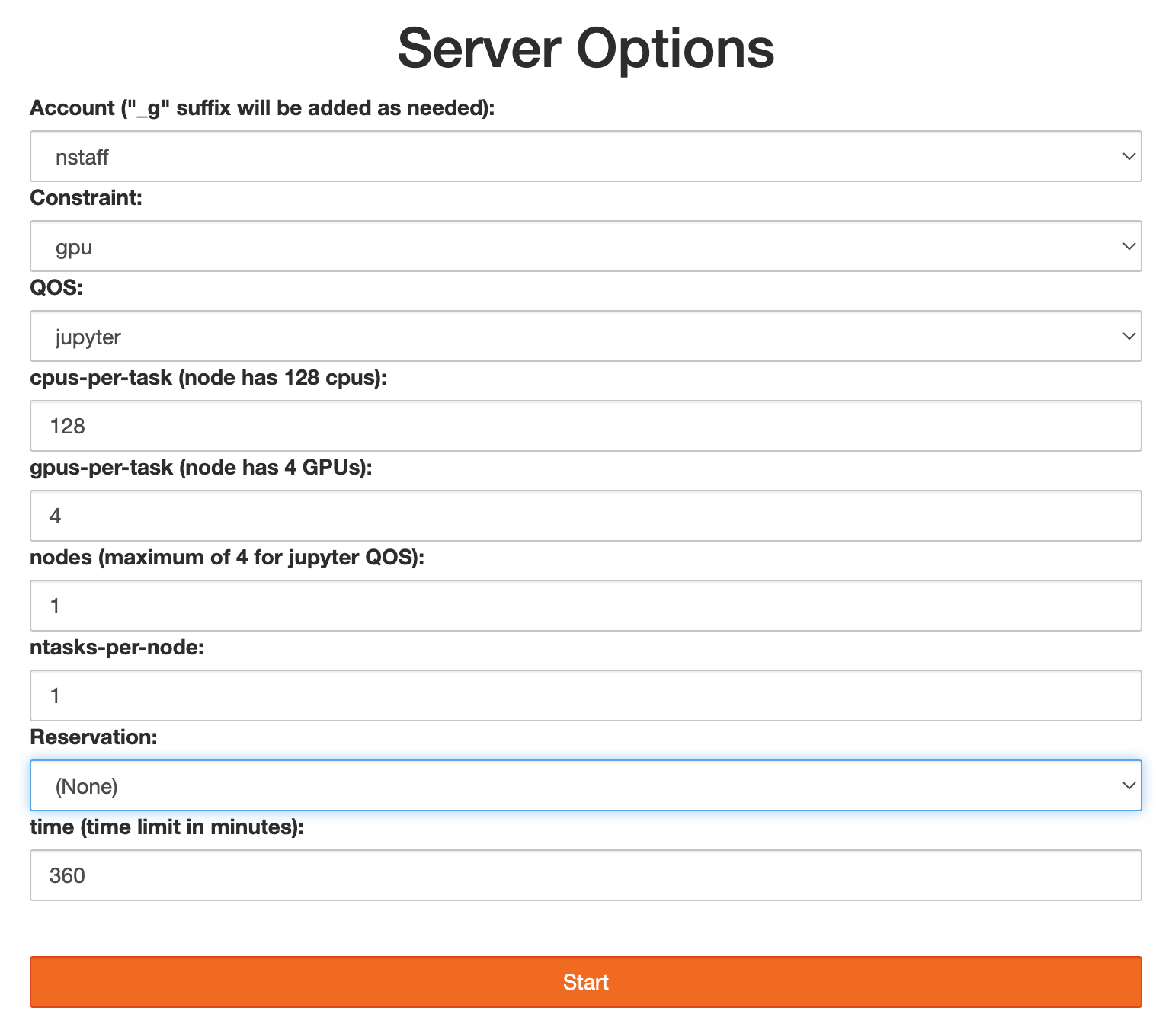
Since this option runs JupyterLab in a batch job you will be charged for use as with shared and exclusively allocated nodes.
JupyterLab Server Logs¶
Logs from login node JupyterLab usage appears in .jupyter-$NERSC_HOST.log in your home directory. At start-up, if you already have one of these log files in place and it is big (1 GB) then it is deleted and a new one is started. Each new JupyterLab server you launch appends to this log file, to help with debugging and retain some history.
Logs from JupyterLab servers launched on compute nodes (shared or exclusive GPU nodes, exclusive CPU nodes, etc.) are written to slurm-<job-id>.out files that appear in your home directory while the job is running.
Kernels Provided by NERSC¶
NERSC maintains some basic kernels for all users. Most of these are based on software environment modules.
For instance, NERSC provides a Python kernel called NERSC Python that works by loading the current default Python module. This means that the Python interpreter and Python packages you use with the NERSC Python kernel in Jupyter are the same as what you would use after typing module load python at the command line. It also means that when the default Python module is updated or changed, the NERSC Python kernel updates or changes along with it.
Other kernels, including ones for PyTorch, TensorFlow, and Julia are also based on software environment modules, but have a slightly different naming convention that should easily translate between the kernel and the module. For example, the tensorflow-2.9.0 kernel loads the tensorflow/2.9.0 module. Additional kernels provided by NERSC may be based on container images or Python environments.