AMReX¶
Background¶
AMReX is a software framework for the development and implementation of massively parallel algorithms using block-structured adaptive mesh refinement (AMR). Block-structured AMR provides the basis for the temporal and spatial discretization strategy for a large variety of applications of interest to the DOE. AMReX provides a unified infrastructure with the functionality needed for applications to be able to effectively and efficiently utilize machines from laptops to exascale accelerator-based architectures. AMR reduces the computational cost and memory footprint compared to a uniform mesh while preserving accurate descriptions of different physical processes in complex multi-physics algorithms. AMReX supports algorithms that solve systems of partial differential equations (PDEs) in simple or complex geometries, and those that use particles and/or particle-mesh operations to represent component physical processes.
Key features of AMReX include:
- Support for block-structured AMR with optional subcycling in time
- Support for cell-centered, face-centered and node-centered data
- Support for hyperbolic, parabolic, and elliptic solves on hierarchical grid structure
- Support for hybrid parallelism model with MPI and OpenMP
- Support for particles, collisions and particle-mesh operations.
- Support for embedded boundary based on the cut-cell methodology
- Support for GPU systems through AMReX's portability layer.
- Basis of mature applications in combustion, astrophysics, cosmology, accelerator physics, multiphase modeling, wind modeling and porous media
- Demonstrated successful scaling on all major DOE supercomputers as well as other large machines
- Source code freely available
AMReX has developed a unique portability layer to achieve high performance on both CPU and GPU based supercomputers. An overview of this layer's design features is presented here:
GPU Porting Strategy¶
AMReX has developed its own portability layer for GPU systems to allow user readability, GPU portability and performance. This layer targets the native programming model for each GPU architechture: CUDA for NVIDIA, HIP for AMD, and DPC++ for Intel, and gives AMReX immediate access to the newest features and performance gains without adding any additional overhead or dependencies.
AMReX's portability layer has been effective by utilizing a flexible system of wrappers designed specifically for its users' needs. AMReX includes well designed loop iterators and specialized launch macros to achieve targetted, optimized performance that is maintainable by AMReX developers and understandable to AMReX users.
One major concern when running on GPU systems is allocation overhead: the cost of allocating and freeing data is substantial and limiting. This is especially true in codes such as AMReX, which regularly changes the problem distribution, fidelity and extent over time. Reducing this overhead has lead to the widespread implementation of memory pools, called Arenas in AMReX, which reuse chunks of contiguous memory to eliminate unneeded allocations and frees. Arena have been integrated into all AMReX data structures, increasing flexibility and control of memory in a performant, tracked manner. The Arenas use a standard alloc and free interface that's portable to CPU and GPU systems:
// Direct use of AMReX's default Arena, 'The_Arena'.
auto dp = (char*)(amrex::The_Arena()->alloc( size ));
amrex::The_Arena()->free(dp);
// Build a new MultiFab in device memory,
// using AMReX's built-in Arena, 'The_Device_Arena'.
// 'mf' Will use this arena for all allocations, resizes and frees.
MultiFab mf(boxarray, distmap, ncomp, nghost,
MFInfo().SetArena(The_Device_Arena()));
// Build a vector that uses a device memory allocator and interacts
// with the memory in a safe, performant manner.
DeviceVector dvect(...);
Once data is properly allocated, accessing data on the device is handled by lightweight, device-friendly objects that contain non-owning pointers and indexing information. For particles, these are the ArrayOfStructs and StructOfArray objects, which allow access to the data in the most performant way. For meshes, this is the Array4 object, which allows a Fortran-like, interface to the underlying data:
MultiFab mf(boxarray, distmap, ncomp, nghost,
MFInfo().SetArena(The_Cpu_Arena()));
// Find the box (the memory block) that contains
// the point of interest.
IntVect cell(/* Target index */);
int comp = /* Target component */;
for (int i=0; i<boxarray.size(); ++i)
{
if (boxarray[i].contains(cell))
{ bx_id = i; break; }
}
// GPU safe, Fortran-like accessor and indexing object.
// This example is done on the CPU.
Array4<Real> arr = mf.array(bx_id);
Real val = arr(cell, comp);
Real valB = arr(cell[0], cell[1], cell[2], comp);
Working on the device with these objects is done through AMReX's lambda launch system, ParallelFor. The ParallelFor launch takes a lambda function and a launch configuration and performs work over the configuration on either the CPU or GPU. AMReX has designed launches for a box of mesh points, a number of particles, or with a user-defined launch configuration. These options cover the majority of parallel algorithms of interest to AMReX's users and developers, allowing AMReX to give highly optimized performance, portable performance.
// Function version of ParallelFor,
// Called over a number of objects, N.
const int MyProc = amrex::ParallelDescriptor::MyProc();
amrex::ParallelFor(N, [=] AMREX_GPU_DEVICE (int idx) noexcept
{
amrex::ULong seed = MyProc*1234567ULL + 12345ULL ;
int seqstart = idx + 10 * idx ;
AMREX_HIP_OR_CUDA( hiprand_init(seed, seqstart, 0, &d_states_d_ptr[idx]);,
curand_init(seed, seqstart, 0, &d_states_d_ptr[idx]); )
});
// Macro version of ParallelFor
// Called over a box, bx, and number of components, ncomp:
Real add = val;
Array4<T> const& a = mf->array();
AMREX_HOST_DEVICE_PARALLEL_FOR_4D(bx, ncomp, i, j, k, n,
{
a(i,j,k,n) += val;
});
These ParallelFor lambda launch calls have been integrated into the workflow of AMReX's custom iterators to create a consistent, portable and performant workflow pattern for users. AMReX's custom iterators, MFIter to iterate over boxes and ParIter to iterate over particles, include GPU workflow control features that create a consistent pattern for users automatically. This pattern is typically the performant option, but can be altered with appropriate flags at runtime. The custom iterators include automatically launching on round-robin rotated GPU streams to complete each iteration's launches in order but independently, explicitly synching the device in the iterator's destructor to ensure safe data use, and optional kernel fusing to reduce launch overhead whenever possible. By creating a default pattern that users is generally optimial but users can tune as needed, the AMReX iterator loops are portable, performant, understandable, and focus on the science:
bool sync = /* Set at iterator destructor. True by default. */
for (MFIter mfi(mf_xi, MFInfo().SetDeviceSync(sync)); mfi.isValid(); ++mfi)
{
// Start on GPU stream "0"
const Box& bx = mfi.tilebox();
auto const& mfab_1 = mf_1.array(mfi);
auto const& mfab_2 = mf_2.array(mfi);
auto const& mfab_3 = mf_3.array(mfi);
// ... Prep first launch
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k) noexcept
{
func_1(i, j, k, mfab_1, obj1);
});
// ... Prep second launch
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k) noexcept
{
func_2(i, j, k, mfab_1, mfab_2, obj2);
});
// ... Prep third launch
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k) noexcept
{
func_3(i, j, k, mfab_2, mfab_3, obj3);
func_4(i, j, k, mfab_1, mfab_3, obj4);
});
// mfi++ operator will cycle to the next GPU stream
} // Device synch in MFIter destructor
From this basic pattern, AMReX has explored a variety of performance optimizations and has established some guidelines for AMReX app developers to use when building GPU codes or porting existing codes to GPUs:
- Build initially in managed memory to make porting easier and allow developers to focus on the most critical features first.
- Whenever possible, put data on the device and leave it there. Additional features, such as Asynchoronous I/O, have been developed in AMReX to help ensure that's possible throughout user's codes. Initially, use this limitation to define the number of GPUs to run across for a given problem's size.
- Inline device functions. Grid-and-particle codes are limited by register usage on modern GPU architechtures. Inlining device operations reduces the number of function pointers, and therefore registers, needed for a given device operation, improving overall performance.
AMReX also includes wrappers and functions for other common operations, including reductions, random number generators, atomics and scans. Some of these operations have been special wrapped with hand-written AMReX code to maximize performance and functionality, such as reductions:
// Reduction to determine the next time step size:
Real estdt = amrex::ReduceMin(S, 0,
[=] AMREX_GPU_HOST_DEVICE (Box const& bx, Array4<Real const> const& fab) -> Real
{
return cns_estdt(bx, fab, dx, *lparm);
});
estdt *= cfl;
ParallelDescriptor::ReduceRealMin(estdt);
and some simply wrap around the available libraries provided by vendors, such as InclusiveSum and ExclusiveSum for CUDA versions greater than 11:
// amrex wrapper around CUB's InclusiveSum
template <typename N, typename T, typename M=std::enable_if_t<std::is_integral<N>::value> >
T InclusiveSum (N n, T const* in, T * out, RetSum a_ret_sum = retSum)
{
#if defined(AMREX_USE_CUDA) && defined(__CUDACC__) && (__CUDACC_VER_MAJOR__ >= 11)
void* d_temp = nullptr;
std::size_t temp_bytes = 0;
AMREX_GPU_SAFE_CALL(cub::DeviceScan::InclusiveSum(d_temp, temp_bytes, in, out, n,
Gpu::gpuStream()));
d_temp = The_Arena()->alloc(temp_bytes);
AMREX_GPU_SAFE_CALL(cub::DeviceScan::InclusiveSum(d_temp, temp_bytes, in, out, n,
Gpu::gpuStream()));
T totalsum = 0;
if (a_ret_sum) {
Gpu::dtoh_memcpy_async(&totalsum, out+(n-1), sizeof(T));
}
Gpu::streamSynchronize();
The_Arena()->free(d_temp);
AMREX_GPU_ERROR_CHECK();
return totalsum;
#elif /* HIP, DPC++ and CPU versions */
...
}
These decisions are made on a case-by-case basis to create an understandable, portable, performant, and manageable framework for AMReX developers and users.
Communications operations have also been heavily optimized for AMReX's GPU port. As the GPUs have substantially reduced calculation time, the relative amount of time spent in communications algorithmsi has skyrocketed. As such, AMReX's halo and copy operations have undergone extensive testing to maximize performance. This includes GPUDirect testing, fusing and buffer packing optimization. In addition, clean, simple, non-blocking versions of the comm operations have been created to allow users to hide latency where possible inside of their applications:
dst.ParallelCopy_nowait(src, src_comp, dst_comp, n_comp);
// Perform work on data sets other than 'dst' while MPI completes.
dst.ParallelCopy_finish();
AMReX apps have found this unique porting strategy to be widely accessable, beneficial and performant:
ExaWind¶

Snapshot of the instantaneous flowfield for an NM-80 rotor using the hybrid ExaWind simulation solver suite. The image shows the tip vortices rendered using q-criterion and the contour colors show the magnitude of the x-velocity field. Credit: Mike Brazell, Ganesh Vijayakumar and Shreyas Ananthan (NREL), AmrWind.
The ExaWind project’s scientific goal is to advance fundamental understanding of the flow physics that govern whole wind plant performance, including wake formation, complex terrain impacts, and turbine-turbine interaction effects. ExaWind uses AMReX for a background structured mesh used to gain considerable speed-ups over a pure unstructured solution. This AMR-based structured code is named AMR-Wind.
AMR-Wind has been able to go from zero to a fully-functional AMReX-based background solver for ExaWind in less than a year using AMReX's incompressible flow solver, incflo, as the starting point. The codebase can run all the target problems on current and pre-exascale hardware. The background solver has been coupled with the structured solver, Nalu-Wind, using an overset-mesh methodology. AMR-Wind has also coupled it to a full-turbine structural solver, OpenFAST, to model structural loading under realistic atmospheric conditions. The top components of AMR-Wind's success are:
-
AMReX's GPU abstractions: The ParallelFor and DeviceVector type abstractions make it easy to develop code quickly. Once the initial code example is in place, application users have been able to adapt for their use cases easily without needed to know the details about the GPU. 80% of the time, users write and test code on CPU and it works on GPU without issues, albeit there's typically tuning that can be done.
-
Linear solvers: MLMG (on structured grid) was critical in achieving AMR-Wind's time-to-solution goals given the problem sizes and spatial scales that have to be resolved. Over the last year, AMReX has added several linear solver enhancements (i.e., overset masking, improvements to hypre interface) that were required to support the hybrid nalu/amr simulations.
Compared to the original Nalu-Wind pathway for ABL/actuator line simulations, AMR-Wind gives a 5x performance benefit on CPUs and GPUs (coming from using MLMG over the AMG/GMRES solvers). Aa 24 hour ABL simulation can be completed in faster than real time (~10 hours). Shreyas Ananthan, ExaWind researcher at NREL, has been able to run a 51.5 billion cell mesh on 4096 summit nodes using GPUs, demonstrating reasonable weak scaling at full scale. This was all unimaginable about a year ago.
Pele¶

Cavity flame: Reflecting shocks in a supersonic channel flow interact with a cavity-stabilized flame that is fueled by direct injection of H2 fuel from the boundary within the cavity. Computed on ORNL’s Summit computer using PeleC, an adaptive mesh compressible combustion code based on the AMReX library.
The Pele project's goal is to enable high fidelity combustion fluid dynamics simulations within complex geometries. It is a suite of applications, mainly PeleLM and PeleC, which perform simulations in the low-mach and compressible regimes, respectively. Here are the highlights of PeleC's implementation of AMReX and capabilities that have been achieved:
PeleC was originally written in BoxLib (which transitioned into AMReX). PeleC adopted a typical programming model for AMR applications which was to do overall application orchestration in C++ and write the computational kernels in Fortran. For targeting Intel Xeon Phi architectures, MPI+OpenMP was introduced which allowed simulations to run with less MPI ranks and increase scalability.
To transition to GPUs, PeleC attempted to keep its Fortran code by developing a prototype of the code using OpenACC. Concurrently, PeleC was prototyped in AMReX's C++ framework for GPUs as well. While performance was found to be quite similar between both prototypes, the C++ method had several advantages for the Pele project, while preserving the Fortran kernels only saved developer time in the short term.
PeleC was originally 12k lines of C++ and 38k lines of Fortran. Using AMReX's C++ framework, PeleC is at the time of this writing, 20k lines of entirely C++ code. PeleC experienced a 2x speedup in simulations on the CPU. The application is able to run on NVIDIA, Intel, and AMD GPUs using their native language implementations as backends in AMReX. Inclusion of the GPU capabilities has also allowed for the MPI+OpenMP model for CPUs to be preserved. Developers of PeleC have found the transition to C++ code to be more readable, more succinct, easier to debug, increased the number of compatible compilers, increased compatibility across the toolchain for code profiling, etc, and generally improved performance.
Utilizing the GPU capabilities in AMReX, PeleC has been demonstrated to scale to 100% of the Summit machine with a parallel efficiency loss of 35%. This was observed when weak scaling from a single Summit node to all of the 4608 available Summit nodes, using 27648 NVIDIA V100 GPUs:
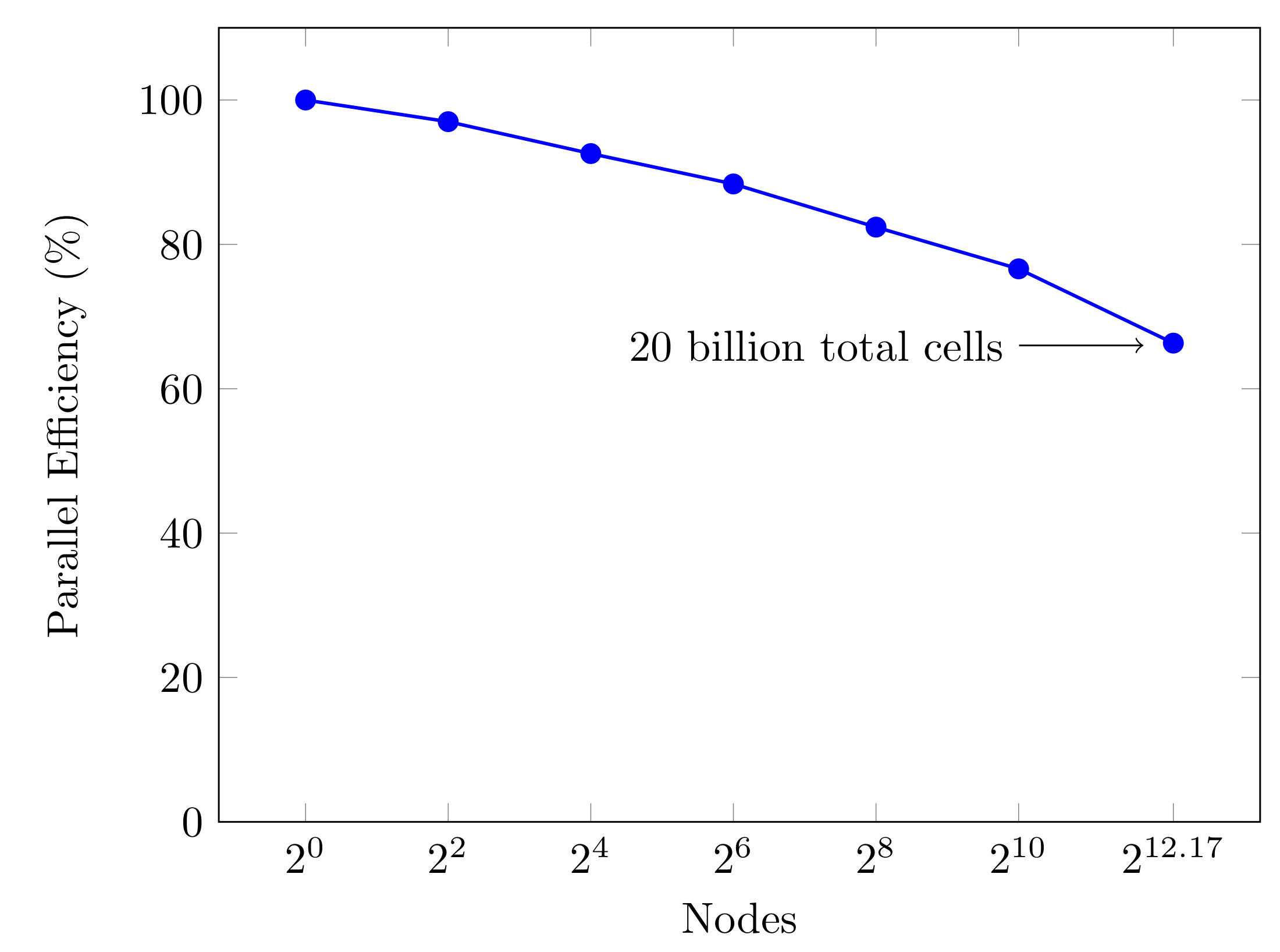
Use of AMReX has also enabled PeleC to demonstrate a 72 billion cell calculation on Summit. Using PeleC on Summit GPUs has improved time to solution for simulations by around 125x when comparing the original Fortran programming model using GCC on Summit CPUs (one MPI rank per CPU core) to the Summit GPUs (one MPI rank per GPU).
In general, the Pele project has stated AMReX to be a lightweight, highly capable, highly scalable, and inviting framework in which to develop their CFD applications.
Links: AMReX Website
Last Updated: Mid April, 2021