Troubleshooting Jobs¶
How do I find which Slurm accounts I am part of?
You can use the iris command line interface to Iris to retrieve user details. The first column Project is all the Slurm accounts a user is associated with.
In this example, the current user is part of two accounts nstaff and m3503.
$ iris
Project Used(user) Allocated(user) Used Allocated
--------- ------------ ----------------- ---------- -----------
m3503 0.0 1000000.0 12726.1 1000000.0
nstaff 21690.5 4000000.0 26397725.1 80000000.0
What is my default Slurm account?
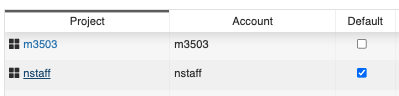
You can find the default user account by logging into https://iris.nersc.gov and navigate to CPU tab, you will see a column Default that shows your default Slurm account. In this example, the user default account is nstaff which means that user job will be charged to nstaff account even if they do not specify #SBATCH -A in their job script.
My job will terminate because it will exceed QOS run time limit, what can I do?
If your job terminates due to QOS run limit, you have a few options:
- Optimize your workflow by profiling your code. We have several profiling tools including HPCToolkit, Perftools, etc. For more details on profilers see performance tools page
- Increase Node/Processor count to reduce runtime.
- Utilize checkpoint/restart via DMTCP
- If all else fails, request a reservation
How do I monitor a job that I submitted?
If you want to monitor your jobs, please use squeue, sqs or sacct and see monitoring page for more details.
Why is my job marked as InvalidQOS?
This indicates you have specified an incorrect QOS name #SBATCH -q <QOS> in your job script. Please check our queue policy for list of available QOSes and correct your job script.
If your account incurs a negative balance, your project will be restricted to the overrun and xfer QOSes. Take for example, project m0001 has a negative balance since it used 75,000 node hours whereas the project limit was 50,000. We can check this using iris command.
$ iris
Project Used(user) Allocated(user) Used Allocated
--------- ------------ ----------------- --------- -----------
m0001*** 750000.0 50000.0 750000.0 50000.0
* = user share of project Negative
** = project balance negative
*** = user and project balance negative
Due to this change, project m0001 will be restricted to a subset of QOSes. If you have previously run jobs on charging QOSes (debug, regular), your jobs will be stuck indefinitely and you should consider killing the jobs using scancel.
Why is my job queued for so long?
The most common cause is that the job requested a long walltime limit: queue wait time correlates strongly with walltime request and weakly with number of nodes (until you reach about half the machine).
The reason for this is the way that jobs are scheduled. Every 5-7 minutes, Slurm makes a plan about what jobs it's going to run for the next 96 hours. It assembles this schedule by going down the list of jobs in priority order, and inserting each into the first empty slot in which it fits. After making that schedule, Slurm scans down the list of jobs not on the schedule, and tries to determine whether it can start each job right now, without having to change anything in its schedule. In other words, it looks for jobs to fill gaps at the front of the schedule. This is why jobs submitted after yours in the regular QOS might start before your jobs.
The characteristics of jobs that are able to fit into those gaps are uniformly that they request a relatively short walltime (generally 4 hours or less; less is better). Until your node count gets up to about half the machine, the number of nodes is not correlated with wait time; it is almost exclusively related to the length of the walltime request.
So, if you can arrange your jobs to use higher node counts for less time (e.g., 48 nodes for 2 hours rather than 2 nodes for 48 hours), they will be more likely to fit into those gaps in the schedule. Another option (for applications that are able to use it) is checkpoint/restart. This also allows you to run your job in the preempt QOS, which offers a substantial discount. If your application doesn't directly support checkpointing, you may still be able to checkpoint it with DMTCP.
Cannot Submit Jobs¶
If you are unable to submit jobs we recommend you check the following
- Check your job script for an error (invalid QOS name, missing walltime limit, invalid node count, etc.).
- Check the Center Status page and see if the system is online.
- Check our queue policies to ensure your job complies with Slurm policies.
- Check your startup configuration files (e.g.,
~/.bashrc,~/.profile) for any user environment variables (e.g.,PATH,LD_LIBRARY_PATH), modules, or aliases that may impact your shell. - Check if you are charging to a correct account (
-A <Account>). If you are not sure of your project name, you can runirisor log in to Iris. - Check if you have a negative balance for your project. If so, please contact your project PI. You can run
iristo see your project details. - Check your file system quotas using
showquota. If your account exceeds a quota limit, you won't be able to submit jobs.
If all else fails, please submit a ticket at http://help.nersc.gov/ with the following details:
- Job script and/or Slurm command
- Output of
module list - Output of warning/error messages
- Time when command was run (use
datecommand) - Add any attachments necessary to troubleshoot issue
Common Errors With Jobs¶
Some common errors encountered during submit or run times and their possible causes are shown in the following table.
Job submission errors¶
-
Error message:
sbatch: error: Your account has exceeded a file system quota and is not permitted to submit batch jobs. Please run `showquota` for more information.Possible causes/remedies:
Your file system usage is over the quota(s). Please run the
showquotacommand to see which quota is exceeded. Reduce usage and resubmit the job. -
Error message:
sbatch: error: Job request does not match any supported policy. sbatch: error: Batch job submission failed: Unspecified error.Possible causes/remedies:
There is something wrong with your job submission parameters and the request (the requested number of nodes, the walltime limit, etc.) does not match the policy for the selected QOS. Please check the queue policy.
-
Error message:
sbatch: error: More resources requested than allowed for logical queue shared (XX requested core-equivalents > YY) sbatch: error: Batch job submission failed: Unspecified errorPossible causes/remedies:
The number of logical cores that your job tries to use exceeds the number that you requested for this
sharedQOS job. -
Error message:
Job submit/allocate failed: UnspecifiedPossible causes/remedies:
This error could happen if a user has no active NERSC project. Please make sure your NERSC account is renewed with an active allocation.
-
Error message:
Job submit/allocate failed: Invalid qos specificationPossible causes/remedies:
This error mostly happens if a user has no access to certain Slurm QOSes. For example, a user who doesn't have access to the
realtimeQOS would see this error when submitting a job to that QOS. -
Error message:
sbatch: error: Batch job submission failed: Socket timed out on send/recv operationPossible causes/remedies:
The job scheduler is busy. Some users may be submitting lots of jobs in a short time span. Please wait a little bit before you resubmit your job.
This error normally happens when submitting a job, but can happen during runtime, too.
-
Error message:
$ salloc ... --qos=interactive salloc: Pending job allocation XXXXXXXX salloc: job XXXXXXXX queued and waiting for resources salloc: error: Unable to allocate resources: Connection timed outPossible causes/remedies:
The interactive job could not start within 6 minutes, and, therefore, was cancelled. It is because either the number of available nodes left from all the reserved interactive nodes. See our "interactive" QOS policy page for more details.
-
Error message:
sbatch: error: No architecture specified, cannot estimate job costs. sbatch: error: Batch job submission failed: Unspecified errorPossible causes/remedies:
Your job didn't specify the type of compute nodes. To run on CPU nodes, add to your batch script:
#SBATCH -C cpuTo request GPU nodes, add this line:
#SBATCH -C gpu -
Error message:
sbatch: error: The overrun logical queue requires an lower balance than the estimated job cost. Job cost estimated at XX.XX NERSC-Hours, your balance is YYYYYY.YY NERSC-Hours (Repo: YYYYYYY.YY NERSC-Hours). Cannot proceed, please see https://docs.nersc.gov/jobs/policy/ for your options to run this job. sbatch: error: Batch job submission failed: Unspecified errorPossible causes/remedies:
You submitted the job to the
overrunQOS directly. When you submit a job with a normal QOS (e.g.,regular,debug, etc.) requesting more NERSC hours than your NERSC project balance, it will be automatically routed to theoverrunQOS. -
Error message:
sbatch: error: No available NERSC-hour balance information for user xxxxx, account yyyyy. Cannot proceed. sbatch: error: Batch job submission failed: Unspecified errorPossible causes/remedies:
You submitted the job using a project that you are not allowed to use. Login in to Iris to see which NERSC projects you can use.
-
Error message:
sbatch: error: Batch job submission failed: Unable to contact Slurm controller (connect failure)Possible causes/remedies:
There may be an issue with Slurm. If the error is still seen after a few minutes, report to NERSC.
-
Error message:
sbatch: error: Job cost estimated at XXXXXXXX.XX NERSC-Hours, your balance is XXXXXXX.XX NERSC-Hours (Repo: XXXXXXXX.XX NERSC-Hours). Cannot proceed, please see https://docs.nersc.gov/jobs/policy/ for your options to run this job. sbatch: error: Job submit/allocate failed: Unspecified errorPossible causes/remedies:
Your remaining NERSC project balance is not big enough to run the job.
-
Error message:
srun: error: Unable to create step for job XXXXXXXX: More processors requested than permittedPossible causes/remedies:
Your
sruncommand required more logical cores than available. Please check the values for-n,-c, etc.
Runtime errors¶
-
Error message:
srun: error: eio_handle_mainloop: Abandoning IO 60 secs after job shutdown initiated.Possible causes/remedies:
Slurm is giving up waiting for stdout/stderr to finish. This typically happens when some rank ends early while others are still wanting to write. If you don't get complete stdout/stderr from the job, please resubmit the job.
-
Error message:
slurmstepd: error: _send_launch_resp: Failed to send RESPONSE_LAUNCH_TASKS: Resource temporarily unavailablePossible causes/remedies:
This situation does not affect the job. This issue may have been fixed.
-
Error message:
srun: fatal: Can not execute vasp_gam /var/spool/slurmd/job15816716/slurm_script: line 17: 34559 Aborted srun -n 32 -c8 --cpu-bind=cores vasp_gamPossible causes/remedies:
The user does not belong to a VASP group. The user needs to provide VASP license info following the instructions.
-
Error message:
$ sqs JOBID ST ... REASON XXXXXXXX PD ... Nodes required* ...or
$ scontrol show job XXXXXXXX ... JobState=PENDING Reason=Nodes_required_for_job_are_DOWN,_DRAINED_or_reserved_for_jobs_in_higher_priority_partitions Dependency=(null) ...Possible causes/remedies:
The job was tentatively scheduled to start as a backfill job but some of the assigned nodes are now down, drained or re-assigned to a higher priority job. Wait until Slurm reschedules the job.
-
Error message:
srun: Job XXXXXXXX step creation temporarily disabled, retryingPossible causes/remedies:
This often happens when there are many
sruncommands in a batch job and compute nodes are not fully completed from the lastsrunbefore the next one starts. Usually the next job step starts eventually.However, if you observe a significant delay with starting a
sruncommand, the problem may have to be examined by NERSC staff. In that case, please report the problem to us. Length of the delay, however, can depend on resources (memory, threads, I/O, etc.) involved in the last job step. -
Error message:
srun: error: Unable to create step for job XXXXXXXX: Job/step already completing or completedwhich appears with or without this message:
srun: Job XXXXXXXX step creation temporarily disabled, retryingPossible causes/remedies:
This may be caused by a system issue. Please report to NERSC.
-
Error message:
/some/path/ ./a.out error while loading shared libraries: /opt/gcc/7.3.0/snos/lib64/libgomp.so.1: cannot read file data: Input/output error ...Possible causes/remedies:
A possible cause is that the
LD_LIBRARY_PATHenvironment variable has been modified. Sincelibgomp.so.1is part of the Intel libraries, you can try unloading thegccmodule withmodule unload gccif it is loaded, or reloading theintelmodule withmodule load intel. -
Error message:
slurmstepd: error: _is_a_lwp: open() /proc/XXXXX/status failed: No such file or directoryPossible causes/remedies:
_is_a_lwpis a function called internally for Slurm job accounting. The message indicates a rare error situation with a function call. But the error shouldn't affect anything in the user job. Please ignore the message. -
Error messages mentioning problems when "locking files", e.g.:
Programs built against the Cray HDF5 or NetCDF libraries may break due to a known bug in a file locking feature.