OpenMP¶
What is OpenMP?¶
OpenMP is an industry standard API of C/C++ and Fortran for shared memory parallel programming. The OpenMP Architecture Review Board (ARB) consists of major compiler vendors and many research institutions. Common architectures include shared memory architecture (multiple CPUs sharing global memory with Uniform Memory Access (UMA) and a typical shared memory programming model of OpenMP or pthreads), distributed memory architecture (each CPU has its own memory with Non-Uniform Memory Access (NUMA) and the typical Message Passing Interface (MPI), and hybrid architecture (UMA within one node or socket, NUMA across nodes or sockets, and the typical hybrid programming model of hybrid MPI/OpenMP). The current architecture trend needs a hybrid programming model with three levels of parallelism: MPI between nodes or sockets, shared memory (such as OpenMP) on the nodes/sockets, and increased vectorization for lower-level loop structures.
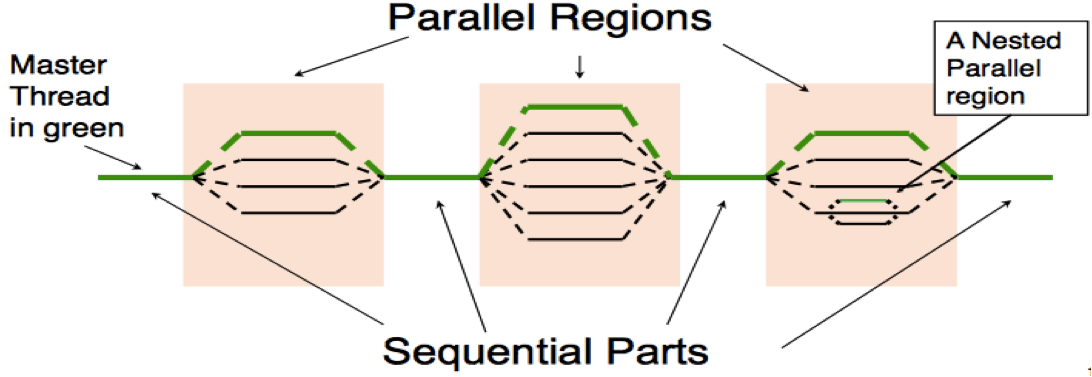
OpenMP has three components: compiler directives and clauses, runtime libraries, and environment variables. The compiler directives are only interpreted when the OpenMP compiler option is turned on. OpenMP uses the "fork and join" execution model: the master thread forks new threads at the beginning of parallel regions, multiple threads share work in parallel; and threads join at the end of parallel regions.
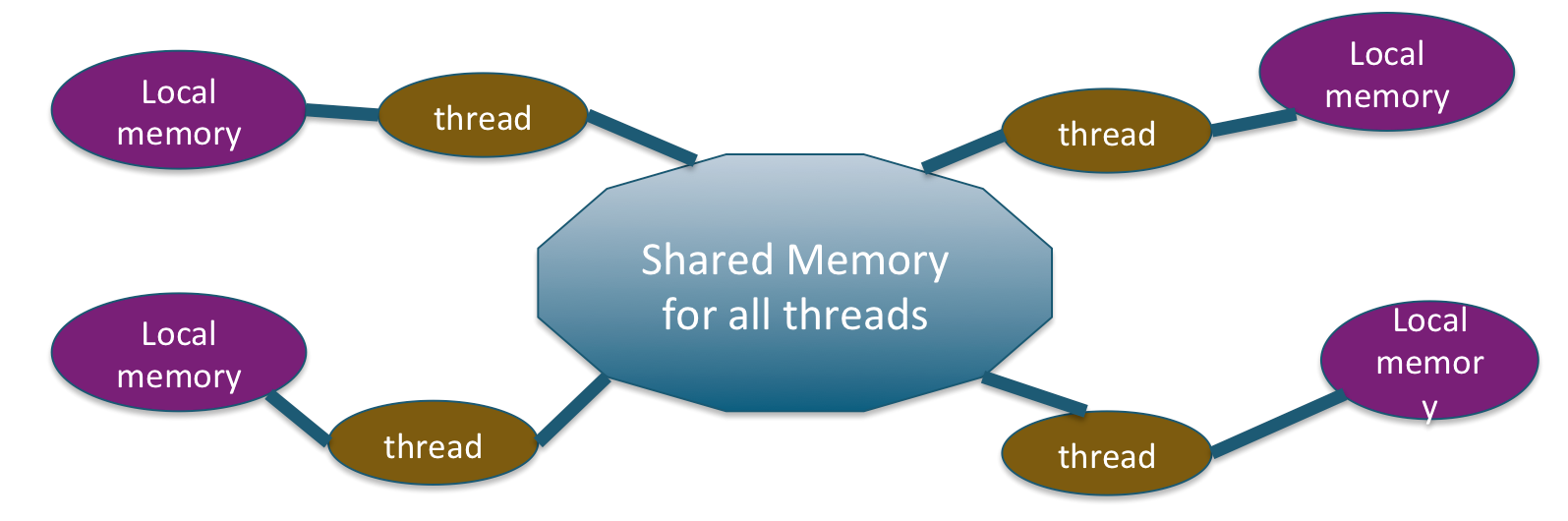
In OpenMP, all threads have access to the same shared global memory. Each thread has access to its own private local memory. Threads synchronize implicitly by reading and writing shared variables. No explicit communication is needed between threads.
The thread that executes the implicit parallel region that surrounds the whole program executes on the host device. OpenMP supports other devices (e.g., GPUs) besides the host device (i.e., CPUs). On Perlmutter, GPUs are available to the host device for offloading code and data. Each device has its own threads that are distinct from threads that execute on another device, and threads cannot migrate from one device to another device. For info on how to offload code and data, please see the OpenMP quickstart guide and HPCSDK OpenMP notes on the Perlmutter Readiness page.
Major features in OpenMP 3.1 include:
- Thread creation with shared and private memory
- Loop parallelism and work sharing constructs
- Dynamic work scheduling
- Explicit and implicit synchronizations
- Simple reductions
- Nested parallelism
- OpenMP tasking
New features in OpenMP 4.0 (released in July 2013) include:
- Device constructs for accelerators
- SIMD constructs for vectorization
- Task groups and dependencies
- Thread affinity control
- User defined reductions
- Cancellation construct
- Initial support for Fortran 2003
OMP_DISPLAY_ENVfor all internal variables
New features in OpenMP 4.5 (released in November 2015) include:
- Significantly improved support for devices
- Support for doacross loops
- New taskloop construct
- Reductions for C/C++ arrays
- New hint mechanisms
- Thread affinity support
- Improved support for Fortran 2003
- SIMD extensions
OpenMP 4.0/4.5 Support in Compilers¶
- GNU compiler
- From gcc/4.9.0 for C/C++ and OpenMP 4.0
- From gcc/4.9.1 for Fortran with OpenMP 4.0
- From gcc/6.0 and most OpenMP 4.5 features
- From gcc/6.1 and full OpenMP 4.5 for C/C++ (not Fortran)
- Intel compiler
- From intel/15.0 with most OpenMP 4.0 features
- From intel/16.0 with full OpenMP 4.0
- From intel/16.0 Update 2 and some OpenMP4.5 SIMD features
- Cray compiler
- From cce/8.4.0 with full OpenMP 4.0
For more information on compiler support for OpenMP, please see the OpenMP compiler support webpage.
More details of using OpenMP can be found in the OpenMP training and resources sections below.
OpenMP Support in Python¶
Python users can use OpenMP directly in Python via a new project called PyOMP.
Relevant NERSC Training Sessions on OpenMP¶
- Advanced OpenMP and CESM Case Study by Helen He, March 2016.
- Nested OpenMP by Helen He, October 2015.
- Tutorial: Getting up to Speed on OpenMP 4.0
- OpenMP Basics and MPI/OpenMP Scaling Helen He. LBNL Computational Sciences Postdocs Training, March 2015.
- Explore MPI/OpenMP Scaling on NERSC Systems by Helen He, NERSC Training, October 2014.
- OpenMP and Vectorization Training by Jack Deslippe, Helen He, Harvey Wasserman, Woo-Sun Yang, October 2014.
- Hybrid MPI/OpenMP Programming by Helen He, NERSC User Group Training, February 2013.
- Introduction to OpenMP by Matt Cordery, NERSC User Group Training, February 2013.
Other Useful OpenMP Resources and Tutorials¶
- Official OpenMP website: OpenMP standards, API specifications, tutorials, forums, and a lot more other information and resources.
- ANL Training Program on Exascale Computing, August 2015
- A "Hands On" Introduction to OpenMP: Part 1 by Bronis de Supinski, LLNL; Tim Mattson, Intel.
- A "Hands On" Introduction to OpenMP: Part 2 by Bronis de Supinski, LLNL; Tim Mattson, Intel.
- A "Hands On" Introduction to OpenMP: Part 3 by Bronis de Supinski, LLNL; Tim Mattson, Intel.
- UC Berkeley ParLab Boot Camp, 2014
- Tim Mattson's (Intel) "Introduction to OpenMP" (2013) on Youtube; 27 video segments, 4 hours total. Intro to OpenMP Slides and Intro to OpenMP exercises.
- LLNL OpenMP Tutorial by Blaise Barney, LLNL.
- UC Berkeley ParLab Boot Camp, 2013
- Shared Memory Programming with OpenMP - Basics by Tim Mattson, Intel. Shared Memory Programming with OpenMP Video.
- More about OpenMP - New Features by Tim Mattson, Intel. More about OpenMP Video.
Tools for OpenMP¶
Tools for tuning OpenMP codes to get better performance include:
- Use Intel Advisor for Threading Design and Vectorization
- Use Intel Inspector to Detect Threading and Memory Issues
- Use Intel VTune for Performance Tuning
- Use Cray Reveal to Insert OpenMP Directives
There are several tools available at NERSC that are useful for tuning OpenMP codes.