DMTCP: Distributed MultiThreaded Checkpointing¶
DMTCP is a transparent checkpoint-restart (C/R) tool that can preserve the state of an arbitrary threaded or distributed application to disk for the purpose of resuming it at a later time or in a different location. Being "transparent" describes how this process requires no modifications to either the application code or the Linux kernel. Additionally, no special system privilege is needed to use DMTCP; it can be operated by users without root access.
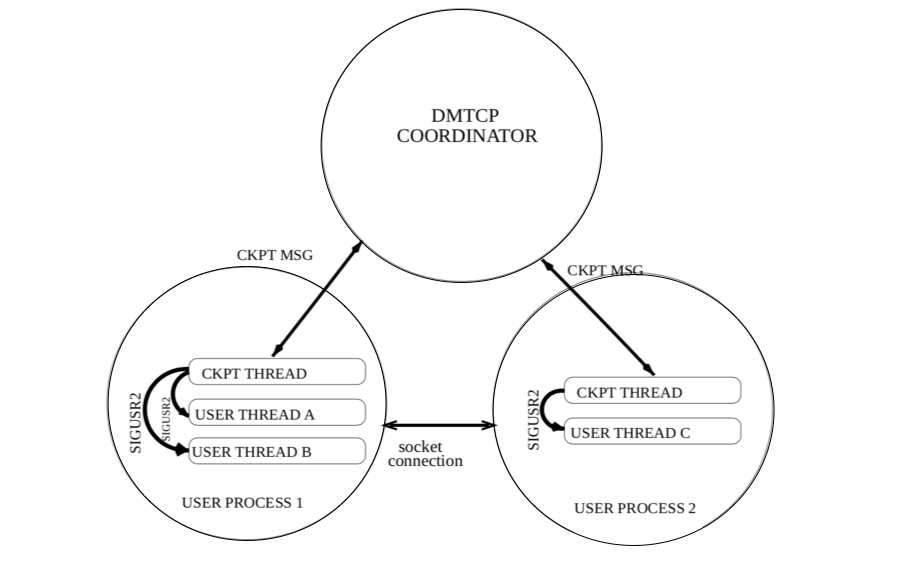
DMTCP uses a central coordinator process to accept user instructions and manage C/R operation as shown in the figure below. There is one DMTCP coordinator for each application to be checkpointed; the dmtcp_coordinator command runs this on one of the nodes allocated to the job. Second, application tasks are started with DMTCP integration using dmtcp_launch which connects to the coordinator. For each user process in the application, a checkpoint thread is spawned that executes C/R instructions from the coordinator. When prompted by either a user command to the coordinator or automatically with a given frequency, DMTCP checkpoints the state of the launched application and preserves everything on disk. The application can then be restarted from the checkpoint data on disk using the dmtcp_restart command.
Note
- Checkpoint files do not overwrite data for older checkpoints, so even if the coordinator fails in the middle of checkpointing, the application can still be resumed from the data in an earlier, undamaged checkpoint.
- DMTCP checkpoint files include the running process memory, context, open files as well as runtime libraries and Linux environment variables, and all the same types of data belonging to any additional processes that have been forked.
- During the checkpoint and restart process, either the DMTCP checkpoint thread or the user threads are active, but never both at the same time.
DMTCP supports a variety of applications, frameworks and programming languages including OpenMP, MATLAB, Python, C, C++, Fortran, shell scripting languages, and workflow management tools.
MPI applications require additional functionality provided by the DMTCP plugin MANA.
Benefits of transparent C/R¶
NERSC users are encouraged to experiment with combining their applications with DMTCP and transparent C/R. Benefits of doing so can include:
- increased job queue throughput by reducing wall time for individual Slurm requests
- the the ability to run jobs of any length despite maximum wall time limits for individual jobs
- 75% charging discount on Perlmutter when using the preempt QOS
- reduce lost progress when system failures occur
- help discover bugs and needs for additional functionality in DMTCP, which we can share with the DMTCP research and development teams
DMTCP on Perlmutter¶
DMTCP is provided to NERSC users as a module on Perlmutter. Load DMTCP with the following command: module load dmtcp
Preparing applications to use DMTCP¶
Using DMTCP to checkpoint and restart applications does not require code modifications, but, it does require that applications be dynamically linked and use shared libraries (.so files) instead of static libraries.
C/R Serial/Threaded Applications with DMTCP¶
C/R Interactive Jobs¶
DMTCP can be used to checkpoint and restart serial/threaded application interactively, which is convenient during testing and debugging. The steps to do so on Perlmutter follow:
Checkpoint¶
-
Obtain a terminal connection to a compute node using the
salloccommand.salloc –N 1 –C cpu –t 1:00:00 -q interactiveLoad the dmtcp module.
module load dmtcp -
Open another terminal, and SSH to the compute node that is allocated for your job. Then start a DMTCP coordinator.
module load dmtcp dmtcp_coordinator -
On the first terminal, launch your application (
a.out) with thedmtcp_launchcommand.dmtcp_launch --join-coordinator ./a.out [arg1 ...] -
While your application is running, on the second terminal you can use the
dmtcp_coordinatorto send C/R commands to your running job. '?' for available commands. Examples include 'c' for checkpointing, 's' for querying the job status, and 'q' for terminating the job.
Restart from a checkpoint¶
-
Same as step 1 above, use
sallocto obtain a terminal on a compute node. -
Repeat earlier step 2 to start the
dmtcp_coordinator. -
Restart the application from a checkpoint using the
dmtcp_restartcommand.dmtcp_restart --join-coordinator ckpt_a.out_*.dmtcp -
As in step 4 above, the terminal running
dmtcp_coordinatorcan be used to send C/R instructions to your running application.
If dmtcp_launch and dmtcp_restart are used without the --join-coordinator flag, they will automatically run a new dmtcp_coordinator, which detaches from its parent process. dmtcp_coordinator can also be run as a daemon (using the --daemon option) in the background (this is useful for batch jobs). dmtcp_command is available to send commands to a coordinator remotely.
dmtcp_command --checkpoint # checkpoint all processes
dmtcp_command --status # query the status
dmtcp_command --quit # kill all processes and quit
All dmtcp_* commands support command line options (use --help to see the list). For instance, periodic checkpointing can be enabled using the -i <checkpoint interval (secs)> option when invoking dmtcp_coordinator, dmtcp_launch or dmtcp_restart commands. If the intended coordinator is running on a different host and/or listening to a port other than 7779, -h <hostname> or -p <port number> options, or the environment variables DMTCP_COORD_HOST and DMTCP_COORD_PORT, can be used to help dmtcp_launch or dmtcp_restart connect to the coordinator.
C/R Batch Jobs¶
The following example components demonstrate the basic use of Slurm scripts to checkpoint and restart an application contained in payload.sh
These examples use helper scripts from the nersc_cr module, which provides a set of bash functions to assist the management C/R jobs. For example, start_coordinator is a bash function that invokes the dmtcp_coordinator command as a daemon in the background, assigns an arbitrary port number for the coordinator, and creates a dmtcp_command script to assist communication with the daemon.
Perlmutter CPU¶
payload.sh: contains the application you wish to checkpoint
#!/bin/bash
for i in {1..15}
do
echo "step $i"
date
sleep 60
done
perlmutter-cpu-dmtcp.sh: launch the application with DMTCP
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q debug
#SBATCH -N 1
#SBATCH -C cpu
#SBATCH -t 00:10:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=00:10:00
#for c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every two minutes
start_coordinator -i 120
#running under dmtcp control
dmtcp_launch -j ./payload.sh
Output of starting perlmutter-cpu-dmtcp.sh
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> sbatch perlmutter-cpu-dmtcp.sh
Submitted batch job 11624834
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> sqs
JOBID ST USER NAME NODES TIME_LIMIT TIME SUBMIT_TIME QOS START_TIME FEATURES NODELIST(REASON
11624834 R elvis test_cr 1 10:00 0:03 2023-07-14T14:35:33 debug 2023-07-14T14:35:34 cpu nid005286
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> ls
ckpt_bash_4f512f17714b4ac4-40000-6a383db3e8d8.dmtcp ckpt_sleep_4f512f17714b4ac4-62000-64b1c153.dmtcp dmtcp_restart_script.sh perlmutter-cpu-dmtcp-vt.sh
ckpt_sleep_4f512f17714b4ac4-50000-64b1bfe6.dmtcp ckpt_sleep_4f512f17714b4ac4-66000-64b1c1cc.dmtcp payload.sh test_cr-11624834.err
ckpt_sleep_4f512f17714b4ac4-54000-64b1c060.dmtcp dmtcp_command.11624834 perlmutter-cpu-dmtcp-restart.sh test_cr-11624834.out
ckpt_sleep_4f512f17714b4ac4-58000-64b1c0d9.dmtcp dmtcp_restart_script_4f512f17714b4ac4-40000-6a3839c2e003.sh perlmutter-cpu-dmtcp.sh
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> cat test_cr-11624834.*
slurmstepd: error: *** JOB 11624834 ON nid005286 CANCELLED AT 2023-07-14T21:45:46 DUE TO TIME LIMIT ***
step 1
Fri 14 Jul 2023 02:35:38 PM PDT
step 2
Fri 14 Jul 2023 02:36:38 PM PDT
step 3
Fri 14 Jul 2023 02:37:39 PM PDT
step 4
Fri 14 Jul 2023 02:38:40 PM PDT
step 5
Fri 14 Jul 2023 02:39:40 PM PDT
step 6
Fri 14 Jul 2023 02:40:41 PM PDT
step 7
Fri 14 Jul 2023 02:41:42 PM PDT
step 8
Fri 14 Jul 2023 02:42:43 PM PDT
step 9
Fri 14 Jul 2023 02:43:43 PM PDT
step 10
Fri 14 Jul 2023 02:44:44 PM PDT
step 11
Fri 14 Jul 2023 02:45:45 PM PDT
perlmutter-cpu-dmtcp-restart.sh: use DMTCP checkpoint files to restart the payload application
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q debug
#SBATCH -N 1
#SBATCH -C cpu
#SBATCH -t 00:10:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=00:10:00
#for c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every two minutes
start_coordinator -i 120
#restarting from dmtcp checkpoint files
./dmtcp_restart_script.sh
Output of using perlmutter-cpu-dmtcp-restart.sh to resume the application in a new Slurm job
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> sbatch perlmutter-cpu-dmtcp-restart.sh
Submitted batch job 11626406
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> sqs
JOBID ST USER NAME NODES TIME_LIMIT TIME SUBMIT_TIME QOS START_TIME FEATURES NODELIST(REASON
11626406 R elvis test_cr 1 10:00 4:02 2023-07-14T15:07:38 debug 2023-07-14T15:07:39 cpu nid004912
elvis@perlmutter:login10:~/checkpoint-restart/dmtcp/examples> cat test_cr-11626406.out
step 11
Fri 14 Jul 2023 03:07:47 PM PDT
step 12
Fri 14 Jul 2023 03:08:48 PM PDT
step 13
Fri 14 Jul 2023 03:09:49 PM PDT
step 14
Fri 14 Jul 2023 03:10:50 PM PDT
step 15
Fri 14 Jul 2023 03:11:50 PM PDT
With modification to Slurm parameters such as --time or --QOS, and the substitution of payload.sh for a real application, this pattern can be used to checkpoint and restart an arbitrary single node workload. When using a QOS which supports pre-emption, the --time-min Slurm parameter in can be used to ensure your application will run for at least that minimum amount of time.
Change the QOS for production workloads
When adapting this and following examples to run a production workload, don't forget to change the requested QOS from debug to another such as regular or preempt.
The dmtcp_restart_script.sh used in the restart job scripts is a bash script generated by the dmtcp_coordinator. It wraps the dmtcp_restart command to use the most recent successful checkpoint files for convenience.
The job dependencies Slurm feature can be used to submit an initial job request, and any number of subsequent restart jobs, all at the same time while guaranteeing no restarts are attempted before the predecessor job has ended.
Note
While a C/R job is running, a checkpoint can be manually triggered, if needed, using the wrapped dmtcp_command command, dmtcp_command.<jobid>, which is automatically created in the working directory of a job. This command can be run from a Perlmutter login node in the working directory of your job as follows:
module load dmtcp
ssh <nidXXXXXX> "cd $(pwd); ./dmtcp_command.<jobid> --checkpoint"
Where the
Automate C/R Jobs¶
C/R job submissions can be further automated using the preemptible job script, such that only a single job script submission is used to operate full checkpoint-restart functionality.
Perlmutter¶
perlmutter-cpu-dmtcp-vt.sh: a sample job script which runs the payload task while DMTCP operates automatically
#!/bin/bash
#SBATCH -J test
#SBATCH -q debug
#SBATCH -N 1
#SBATCH -C cpu
#SBATCH -t 00:06:00
#SBATCH -e %x-%j.err
#SBATCH -o %x-%j.out
#SBATCH --time-min=00:06:00
#SBATCH --comment=00:17:00
#SBATCH --signal=B:USR1@60
#SBATCH --requeue
#SBATCH --open-mode=append
#for c/r jobs
module load dmtcp nersc_cr
start_coordinator
#c/r jobs
if [[ $(restart_count) == 0 ]]; then
#user setting
dmtcp_launch -j ./payload.sh &
elif [[ $(restart_count) > 0 ]] && [[ -e dmtcp_restart_script.sh ]]; then
./dmtcp_restart_script.sh &
else
echo "Failed to restart the job, exit"; exit
fi
# requeueing the job if remaining time >0
ckpt_command=ckpt_dmtcp #additional checkpointing right before the job hits the wall limit
requeue_job func_trap USR1
wait
This script uses the same basic concepts as the manual start and restart scripts above, but adds automation to reduce the manual actions needed to operate checkpoint-restart functions. As a result the single script submission to Slurm can manage the entire process.
-
The Slurm comment field is used to set and track the maximum total compute time which can be requested by the first job and all requeued jobs. If job time expires and its task is still running, a checkpoint is created, the job is requeued, and the comment field updated to reflect how much time remains.
-
As the simplest example, the job is not automatically checkpointed with a timed schedule, but only does so when receiving the system signal from Slurm that it is about to be ended. If scheduled checkpoints are still desired, return the
-iflag to thestart_coordinatorcommand. -
There is only one job id, and one standard output/error file associated with multiple requeued jobs. The Slurm
sacctcommand accepts a--duplicatesflag which can be used to display more complete information about requeued jobs.
These features are enabled with the following additional sbatch flags and a bash function requeue_job, which traps the signal (USR1) sent from Slurm:
#SBATCH --comment=12:00:00 #maximum time available to job and all requeued jobs
#SBATCH --signal=B:USR1@60
#SBATCH --requeue #specify job is requeueable
#SBATCH --open-mode=append #to append standard out/err of the requeued job
#to that of the previously terminated job
#requeueing the job if remaining time >0
ckpt_command=ckpt_dmtcp
requeue_job func_trap USR1
wait
where the --comment sbatch flag is used to specify the desired walltime and to track the remaining walltime for the job (after pre-termination). You can specify any length of time, e.g., a week or even longer. The --signal flag is used to request that the batch system sends user-defined signal USR1 to the batch shell (where the job is running) sig_time seconds (e.g., 60) before the job hits the wall limit. i
Upon receiving the signal USR1 from the batch system 60 seconds before the job hits the wall limit, the requeue_job executes the following commands (contained in a function func_trap provided on the requeue_job command line in the job script):
dmtcp_command --checkpoint #checkpoint the job if ckpt_command=ckpt_dmtcp
scontrol requeue $SLURM_JOB_ID #requeue the job
If your job completes before the job hits the wall limit it will exit normally; the batch system will not send the USR1 signal, and the two commands above will not be executed (no additional checkpointing and no additional requeued job).
For more details about the requeue_job and other functions used in the C/R job scripts, refer to the script cr_functions.sh provided by the nersc_cr module. (type module show nersc_cr to see where the script resides). You may consider making a local copy of this script, and modifying it for your use case.
To run the job, simply submit the job script,
sbatch vim perlmutter-cpu-dmtcp-vt.sh
Note
-
It is important to make the
dmtcp_launchanddmtcp_restart_script.shrun in the background (&), and add a wait command at the end of the job script, so that when the batch system sends the USR1 signal to the batch shell, the wait command gets killed, instead of thedmtcp_launchordmtcp_restart_script.shcommands, so that they can continue to run to complete the last checkpointing right before the job hits the wall limit. -
The
sig_timein the--signalsbatch flag should match or exceed match the checkpoint overhead of your job. -
Though one checkpoint at the end of a job is automated, setting the checkpoint interval for your job may still be useful for recovering from application failures.
C/R MPI Applications with MANA¶
NERSC supports MANA for checkpointing/restarting MPI applications on Perlmutter, which works with any MPI implementation and network, including Cray MPICH. MANA is implemented as a plugin in DMTCP, and users the dmtcp_coordinator, dmtcp_launch, dmtcp_restart, and dmtcp_command as described above, but with additional command line options. See the MANA page for additional information about checkpointing/restarting MPI applications.
DMTCP Help Pages¶
dmtcp_coordinator help page
elvis@perlmutter:login29:~> dmtcp_coordinator --help
Usage: dmtcp_coordinator [OPTIONS] [port]
Coordinates checkpoints between multiple processes.
Options:
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port to listen on (default: 7779)
--port-file filename
File to write listener port number.
(Useful with '--port 0', which is used to assign a random port)
--status-file filename
File to write host, port, pid, etc., info.
--ckptdir (environment variable DMTCP_CHECKPOINT_DIR):
Directory to store dmtcp_restart_script.sh (default: ./)
--tmpdir (environment variable DMTCP_TMPDIR):
Directory to store temporary files (default: env var TMDPIR or /tmp)
--write-kv-data:
Writes key-value store data to a json file in the working directory
--exit-on-last
Exit automatically when last client disconnects
--kill-after-ckpt
Kill peer processes of computation after first checkpoint is created
--timeout seconds
Coordinator exits after <seconds> even if jobs are active
(Useful during testing to prevent runaway coordinator processes)
--daemon
Run silently in the background after detaching from the parent process.
-i, --interval (environment variable DMTCP_CHECKPOINT_INTERVAL):
Time in seconds between automatic checkpoints
(default: 0, disabled)
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
-q, --quiet
Skip startup msg; Skip NOTE msgs; if given twice, also skip WARNINGs
--help:
Print this message and exit.
--version:
Print version information and exit.
COMMANDS:
type '?<return>' at runtime for list
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_launch help page
elvis@perlmutter:login29:~> dmtcp_launch --help
Usage: dmtcp_launch [OPTIONS] <command> [args...]
Start a process under DMTCP control.
Connecting to the DMTCP Coordinator:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--port-file FILENAME
File to write listener port number. (Useful with
'--coord-port 0', which is used to assign a random port)
-j, --join-coordinator
Join an existing coordinator, raise error if one doesn't
already exist
--new-coordinator
Create a new coordinator at the given port. Fail if one
already exists on the given port. The port can be specified
with --coord-port, or with environment variable
DMTCP_COORD_PORT.
If no port is specified, start coordinator at a random port
(same as specifying port '0').
--any-coordinator
Use --join-coordinator if possible, but only if port was specified.
Else use --new-coordinator with specified port (if avail.),
and otherwise with the default port: --port 7779)
(This is the default.)
-i, --interval SECONDS (environment variable DMTCP_CHECKPOINT_INTERVAL)
Time in seconds between automatic checkpoints.
0 implies never (manual ckpt only);
if not set and no env var, use default value set in
dmtcp_coordinator or dmtcp_command.
Not allowed if --join-coordinator is specified
Checkpoint image generation:
--gzip, --no-gzip, (environment variable DMTCP_GZIP=[01])
Enable/disable compression of checkpoint images (default: 1)
WARNING: gzip adds seconds. Without gzip, ckpt is often < 1s
--ckptdir PATH (environment variable DMTCP_CHECKPOINT_DIR)
Directory to store checkpoint images
(default: curr dir at launch)
--ckpt-open-files
--checkpoint-open-files
Checkpoint open files and restore old working dir.
(default: do neither)
--allow-file-overwrite
If used with --checkpoint-open-files, allows a saved file
to overwrite its existing copy at original location
(default: file overwrites are not allowed)
--ckpt-signal signum
Signal number used internally by DMTCP for checkpointing
(default: SIGUSR2/12).
Enable/disable plugins:
--with-plugin (environment variable DMTCP_PLUGIN)
Colon-separated list of DMTCP plugins to be preloaded with
DMTCP.
(Absolute pathnames are required.)
--batch-queue, --rm
Enable support for resource managers (Torque PBS and SLURM).
(default: disabled)
--ptrace
Enable support for PTRACE system call for gdb/strace etc.
(default: disabled)
--modify-env
Update environment variables based on the environment on the
restart host (e.g., DISPLAY=$DISPLAY).
This can be set in a file dmtcp_env.txt.
(default: disabled)
--pathvirt
Update file pathnames based on DMTCP_PATH_PREFIX
(default: disabled)
--ib, --infiniband
Enable InfiniBand plugin. (default: disabled)
--disable-alloc-plugin: (environment variable DMTCP_ALLOC_PLUGIN=[01])
Disable alloc plugin (default: enabled).
--disable-dl-plugin: (environment variable DMTCP_DL_PLUGIN=[01])
Disable dl plugin (default: enabled).
--disable-all-plugins (EXPERTS ONLY, FOR DEBUGGING)
Disable all plugins.
Other options:
--tmpdir PATH (environment variable DMTCP_TMPDIR)
Directory to store temp files (default: $TMDPIR or /tmp)
(Behavior is undefined if two launched processes specify
different tmpdirs.)
-q, --quiet (or set environment variable DMTCP_QUIET = 0, 1, or 2)
Skip NOTE messages; if given twice, also skip WARNINGs
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
--help
Print this message and exit.
--version
Print version information and exit.
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_restart help page
elvis@perlmutter:login29:~> dmtcp_restart --help
Usage: dmtcp_restart [OPTIONS] <ckpt1.dmtcp> [ckpt2.dmtcp...]
Usage (MPI): dmtcp_restart [OPTIONS] --restartdir [DIR w/ ckpt_rank_*/ ]
Restart processes from a checkpoint image.
Connecting to the DMTCP Coordinator:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--port-file FILENAME
File to write listener port number.
(Useful with '--port 0', in order to assign a random port)
-j, --join-coordinator
Join an existing coordinator, raise error if one doesn't
already exist
--new-coordinator
Create a new coordinator at the given port. Fail if one
already exists on the given port. The port can be specified
with --coord-port, or with environment variable
DMTCP_COORD_PORT.
If no port is specified, start coordinator at a random port
(same as specifying port '0').
--any-coordinator
Use --join-coordinator if possible, but only if port was specified.
Else use --new-coordinator with specified port (if avail.),
and otherwise with the default port: --port 7779)
(This is the default.)
-i, --interval SECONDS (environment variable DMTCP_CHECKPOINT_INTERVAL)
Time in seconds between automatic checkpoints.
0 implies never (manual ckpt only); if not set and no env
var, use default value set in dmtcp_coordinator or
dmtcp_command.
Not allowed if --join-coordinator is specified
Other options:
--no-strict-checking
Disable uid checking for checkpoint image. Allow checkpoint
image to be restarted by a different user than the one
that created it. And suppress warning about running as root.
(environment variable DMTCP_DISABLE_STRICT_CHECKING)
--ckptdir (environment variable DMTCP_CHECKPOINT_DIR):
Directory to store checkpoint images
(default: use the same dir used in previous checkpoint)
--restartdir Directory that contains checkpoint image directories
--mpi Use as MPI proxy (default: no MPI proxy)
--tmpdir PATH (environment variable DMTCP_TMPDIR)
Directory to store temp files (default: $TMDPIR or /tmp)
-q, --quiet (or set environment variable DMTCP_QUIET = 0, 1, or 2)
Skip NOTE messages; if given twice, also skip WARNINGs
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
--debug-restart-pause (or set env. var. DMTCP_RESTART_PAUSE =1,2,3 or 4)
dmtcp_restart will pause early to debug with: GDB attach
--help
Print this message and exit.
--version
Print version information and exit.
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_command help page
elvis@perlmutter:login29:~> dmtcp_command --help
Usage: dmtcp_command [OPTIONS] COMMAND [COMMAND...]
Send a command to the dmtcp_coordinator remotely.
Options:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--help
Print this message and exit.
--version
Print version information and exit.
Commands for Coordinator:
-s, --status: Print status message
-l, --list: List connected clients
-c, --checkpoint: Checkpoint all nodes
-bc, --bcheckpoint: Checkpoint all nodes, dmtcp_command blocks until done
-kc, --kcheckpoint Checkpoint all nodes, kill all nodes when done
-i, --interval <val> Update ckpt interval to <val> seconds (0=never)
-k, --kill Kill all nodes
-q, --quit Kill all nodes and quit
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
Resources¶
- DMTCP website
- DMTCP github
- DMTCP user training slides (Nov. 2019)
- dmtcp modules on Cori used https://github.com/JainTwinkle/dmtcp.git (branch: spades-v2)
- MANA for MPI: MPI-Agnostic Network-Agnostic Transparent Checkpointing